
Transformers Laid Out
I have encountered that there are mainly three types of blogs/videos/tutorials talking about transformers
- Explaining how a transformer works (One of the best is Jay Alammar’s blog)
- Explaining the “Attention is all you need” paper (The Annotated Transformer)
- Coding tranformers in PyTorch (Coding a ChatGPT Like Transformer From Scratch in PyTorch)
Each follows an amazing pedagogy, Helping one understand a singular concept from multiple point of views. (This blog has been highly influenced by the above works)
Here I aim to:
- Give an intuition of how transformers work
- Explain what each section of the paper means and how you can understand and implement it
- Code it down using PyTorch from a beginners perspective
All in one place.
How to use this blog
I will first give you a quick overview of how the transformer works and why it was developed in the first place.
Once we have a baseline context setup, We will dive into the code itself.
I will mention the section from the paper and the part of the transformer that we will be coding, along with that I will give you a sample code block with hints and links to documentation like the following:
class TransformerLRScheduler:
def __init__(self, optimizer, d_model, warmup_steps):
"""
Args:
optimizer: Optimizer to adjust learning rate for
d_model: Model dimensionality
warmup_steps: Number of warmup steps
"""
#YOUR CODE HERE
def step(self, step_num):
"""
Update learning rate based on step number
"""
# lrate = d_model^(-0.5) * min(step_num^(-0.5), step_num * warmup_steps^(-1.5))
#YOUR CODE HERE - implement the formula
I will add helpful links after the code block, but I will recommend you do your own research first. That is the first steps to becoming a cracked engineer
I recommend you copy these code blocks and try to implement them by yourself.
To make it easier, before we start coding I will explain each part in detail. If you are still unable to solve it, come back and see my implementation.
Understanding the Transformer
The original transformers was made for machine translation task and that is what we shall do as well. We will try to translate “I like Pizza” from English to Hindi.
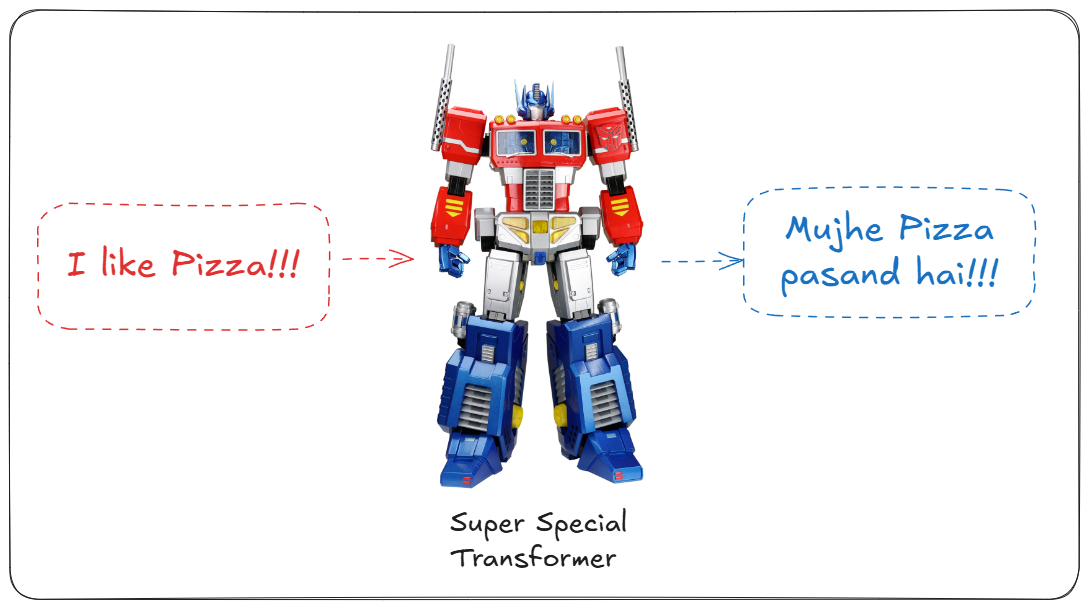
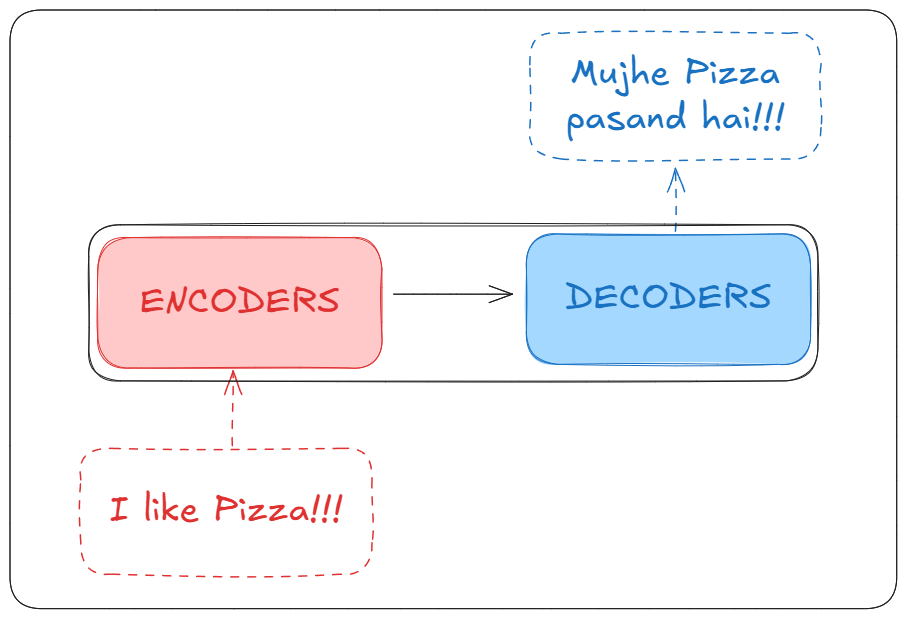
But before that, Let’s have a brief look into the blackbox that is our Transformer. We can see that it consists of Encoders and Decoders
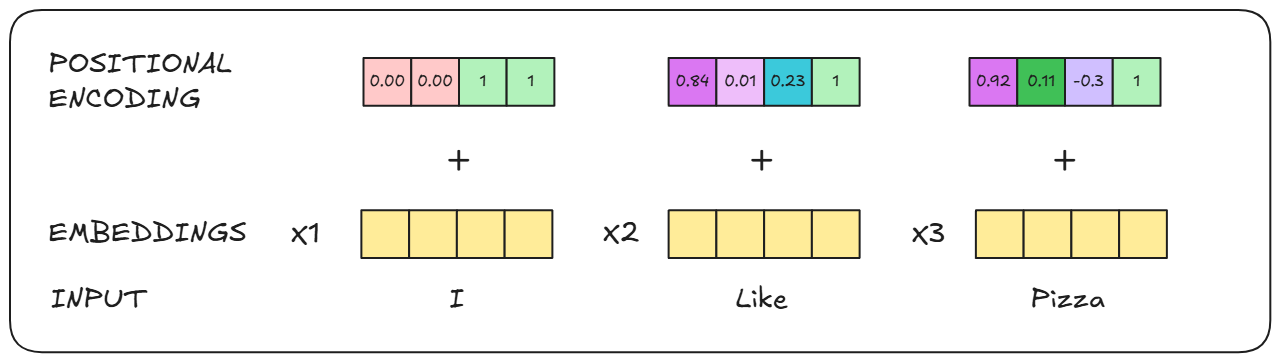
Before being passed to the Encoder, The sentence “I like Pizza” is broken down into it’s respective words* and each word is embedded using an embeddings matrix. (which is trained along with the transformer)

To these embeddings positional information is added.
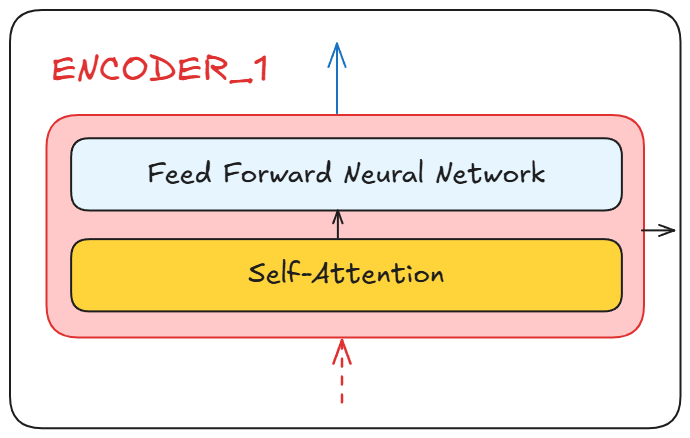
After that these embeddings are passed to the encoder block which essentially does two things
- Applies self-attention to understand the relationship of individual words with respect to the other word present
- Output self-attention scores to a feed forward network
The decoder block takes the output from the encoder, runs it through it self, produces an output ,and sends it back to itself to create the next word
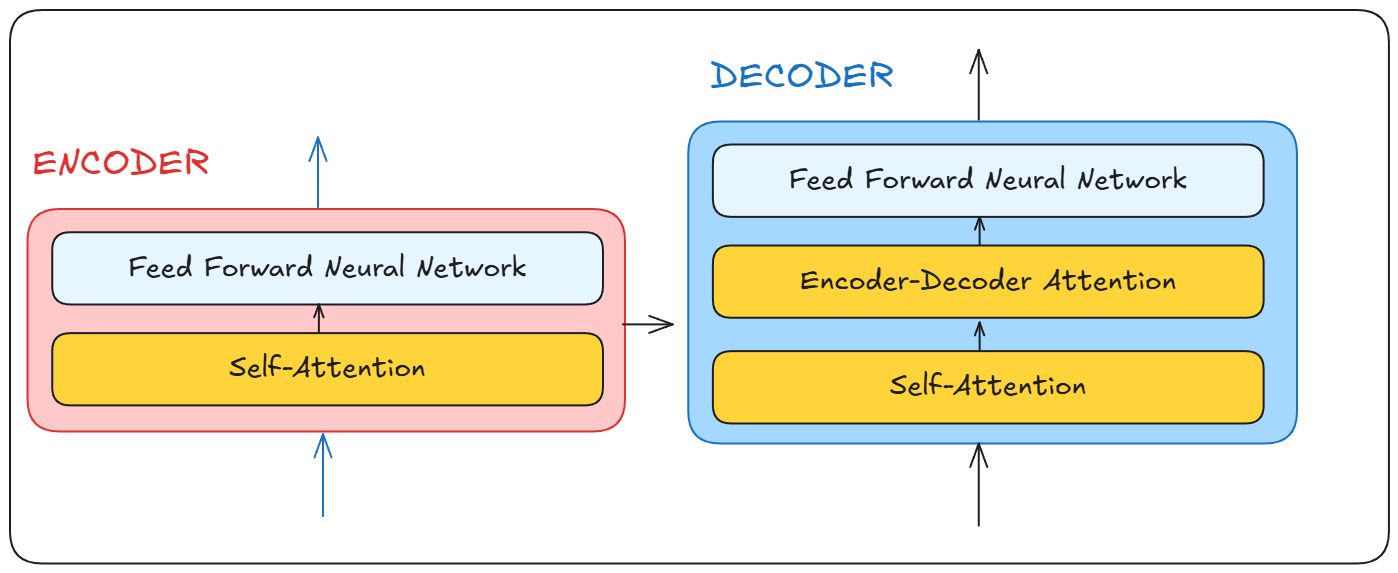
Think of it like this. The encoder understands your language let’s call it X and another language called Y The decoder understands Y and the language you are trying to translate X to, lets call it Z.
So Y acts as the common language that both the encoder and decoder speak to produce the final output.
*We are using words for easier understanding, most modern LLMs do not work with words. But rather “Tokens”
Understanding Self-attention
I created a video with a better visualization of what is going on, consider checking it out
We have all heard of the famous trio, “Query, Key and Values”. I absolutely lost my head trying to understand how the terms came up behind this idea Was Q,K,Y related to dictionaries? (or maps in traditional CS) Was it inspired by a previous paper? if so how did they come up with?
Let us first build an intuition behind the idea.
Sentence (S): “Pramod loves pizza”
Question:
- Who loves pizza?
You can come up with as many Questions (the queries) for the sentence as you want. Now for each query, you will have one specific piece of information (the key) that will give you the desired answer (the value)
Query:
- Q ->Who loves pizza?
K -> pizza, Pramod, loves (it will actually have all the words with different degree of importance)
V -> pizza (The value is not directly the answer, but a representation as a matrix of something similar to the answer)
This is an over simplification really, but it helps understand that the queries, keys and values all can be created only using the sentences.
Let us first understand how Self-attention is applied and subsequently understand why is it even done. Also, for the rest of the explanation treat Q,K,V purely as matrices and nothing else.
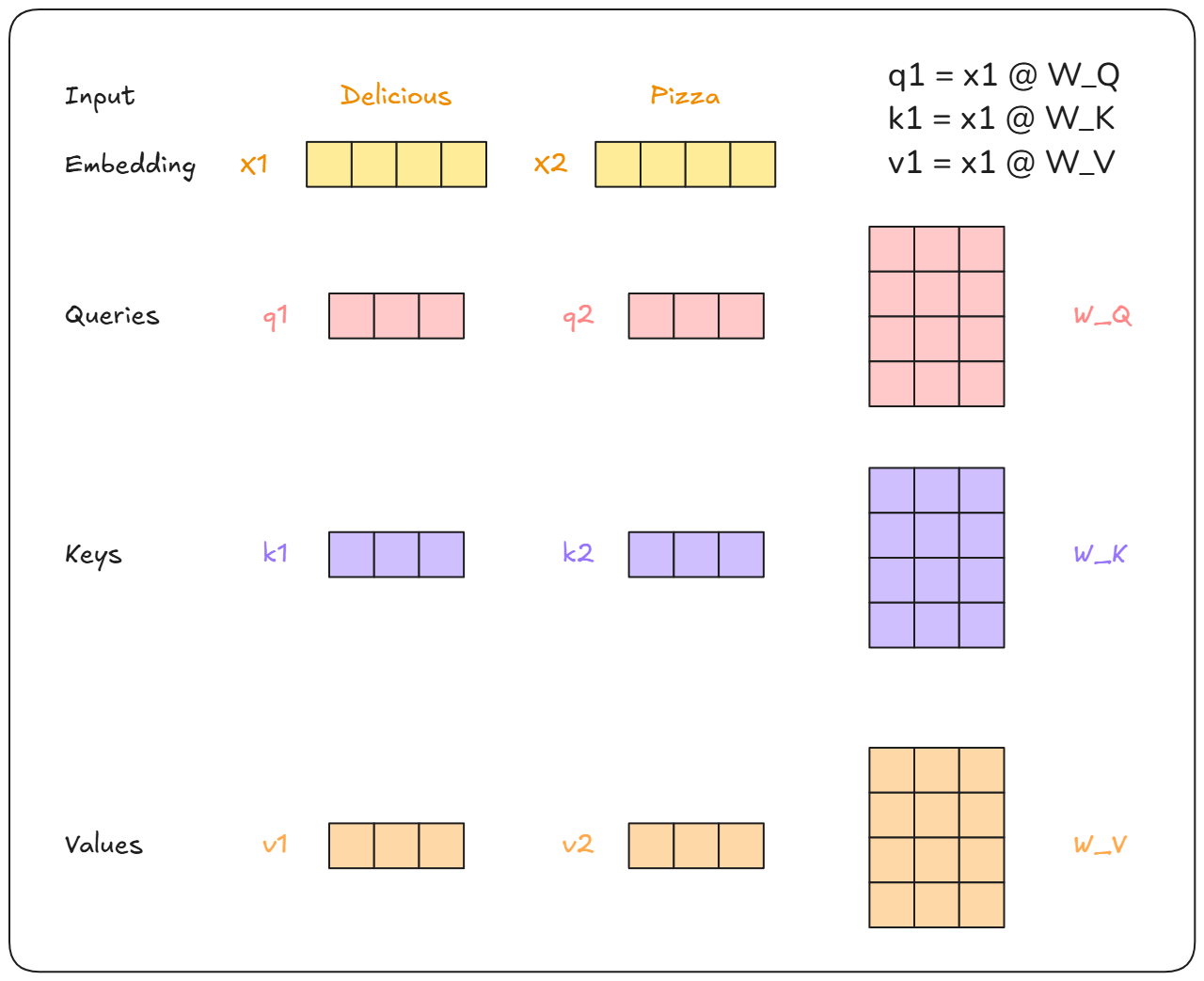
First, The word “Delicious Pizza” is converted into embeddings. Then it is multiplied with the weights W_Q, W_K, W_V to produce Q,K,V vectors.
These weights W_Q, W_K, W_V are trained alongside with the transformer. Notice how vector Q,K,V are smaller than the size of x1,x2. Namely, x1,x2 are vectors of size 512. Whereas Q,K,V are of size 64. This is an architectural choice to make the computation smaller and faster.
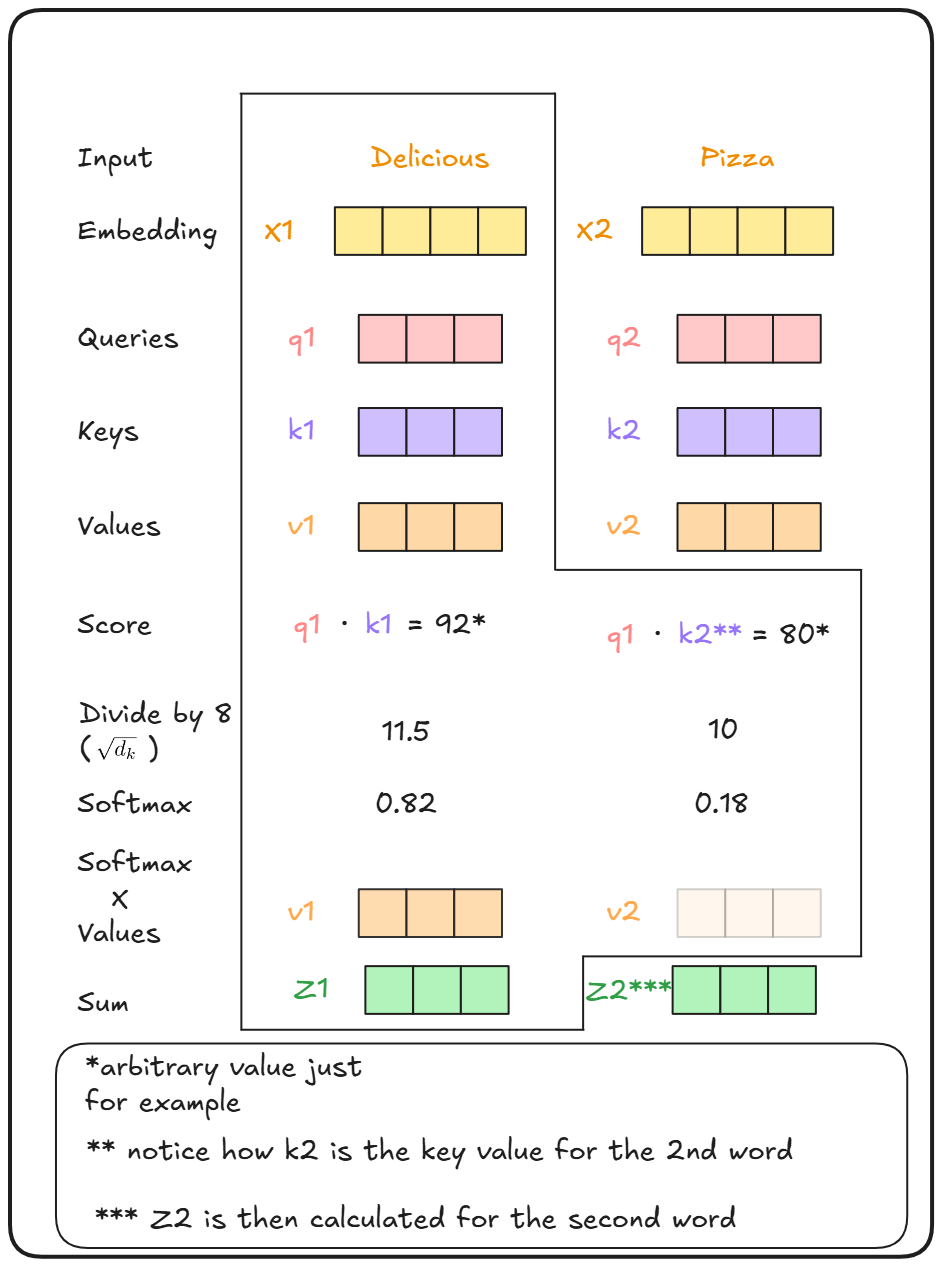
Now using these Q,K,V vectors the attention score is calculated.
Calculating the attention score for the first word “Delicious” we take the query (q1) and key (k1) of the word and take a dot product of them. (Dot products are great to find similarity between things).
Then we divide that by Square root of the dimension of key vector. This is done to stabilize training.
The same process is done with the query of word one (q1) and all the keys of the different words in this case k1 & k2.
Finally using all the values, we take a softmax of each out.
Then these are multiplied with the value of each word (v1,v2). Intuitvely to get the importance of each word with respect to the selected words. Less important words are drowned out by lets say multipling with 0.001.
And finally everything is summed up to get the Z vector
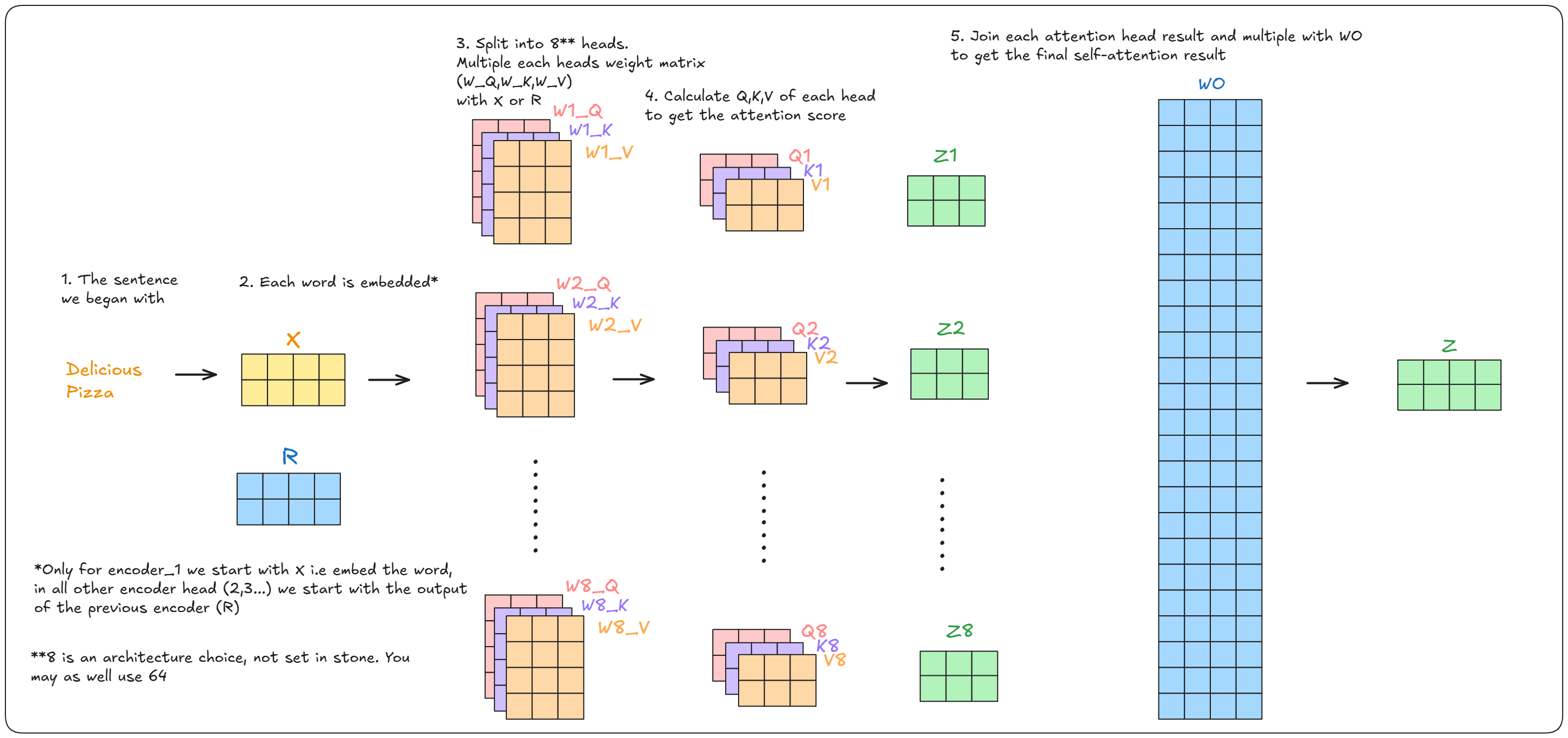
The thing that made transformers was that computation could be parallelized, So we do not deal with vectors. But rather matrices.
The implementation remains the same.
First calulate Q,K,V Matrix
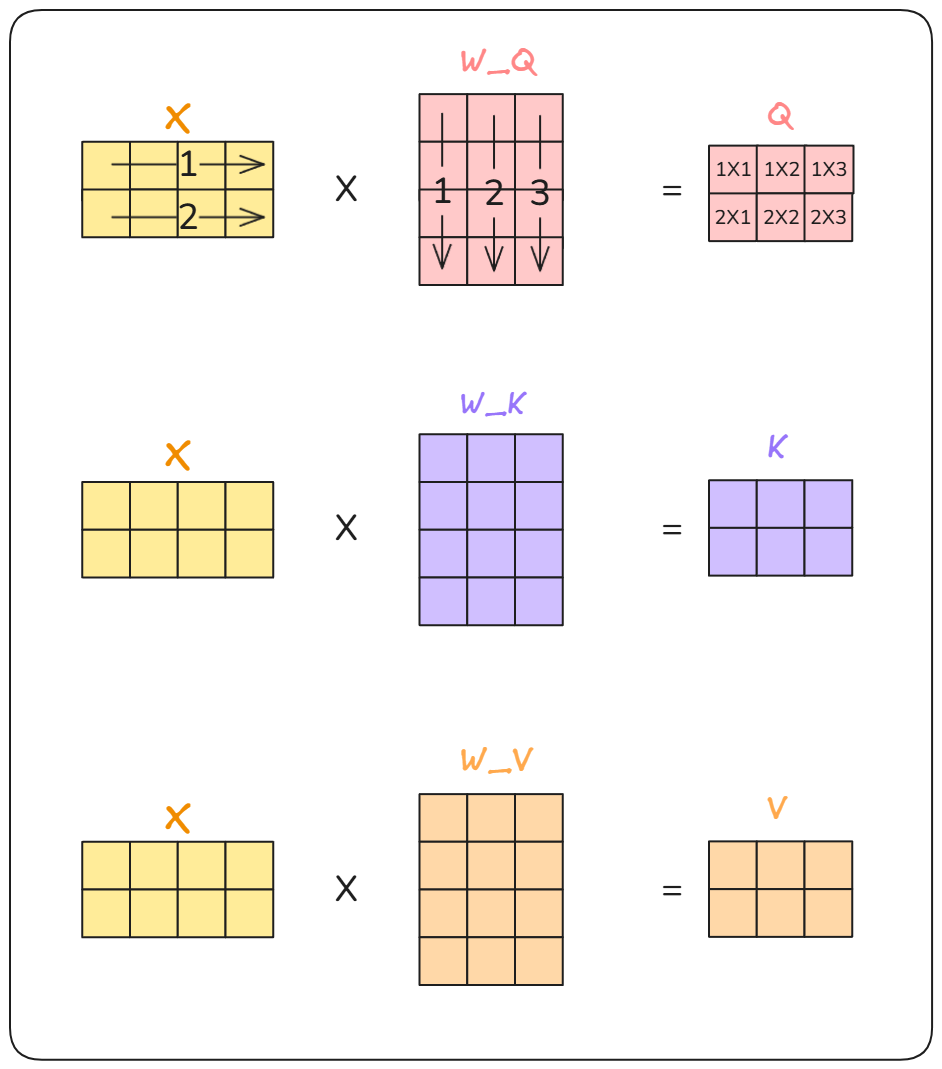
Second calculate the attention scores
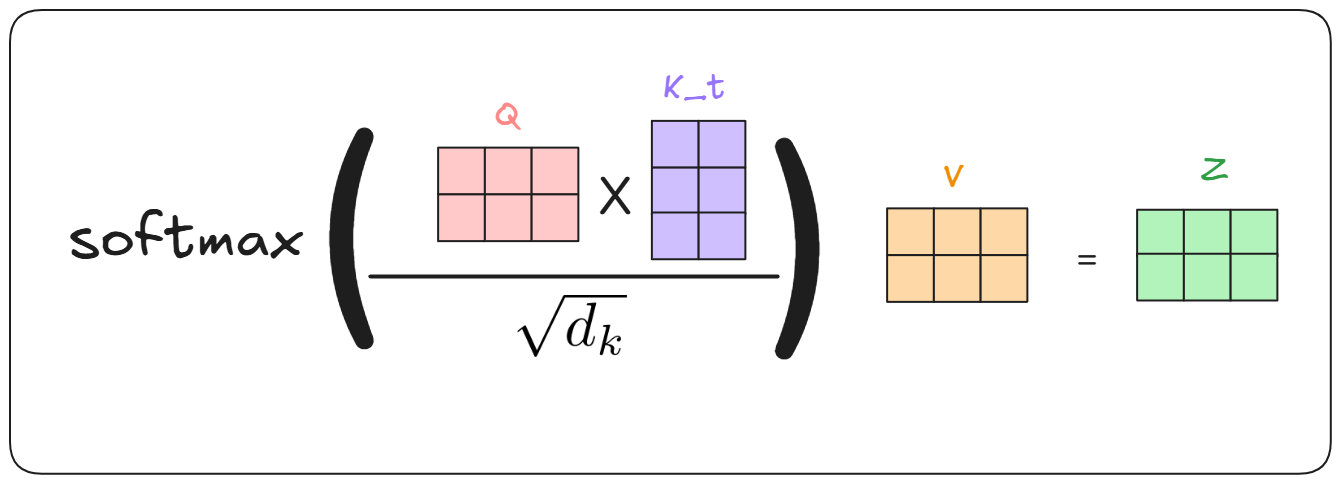
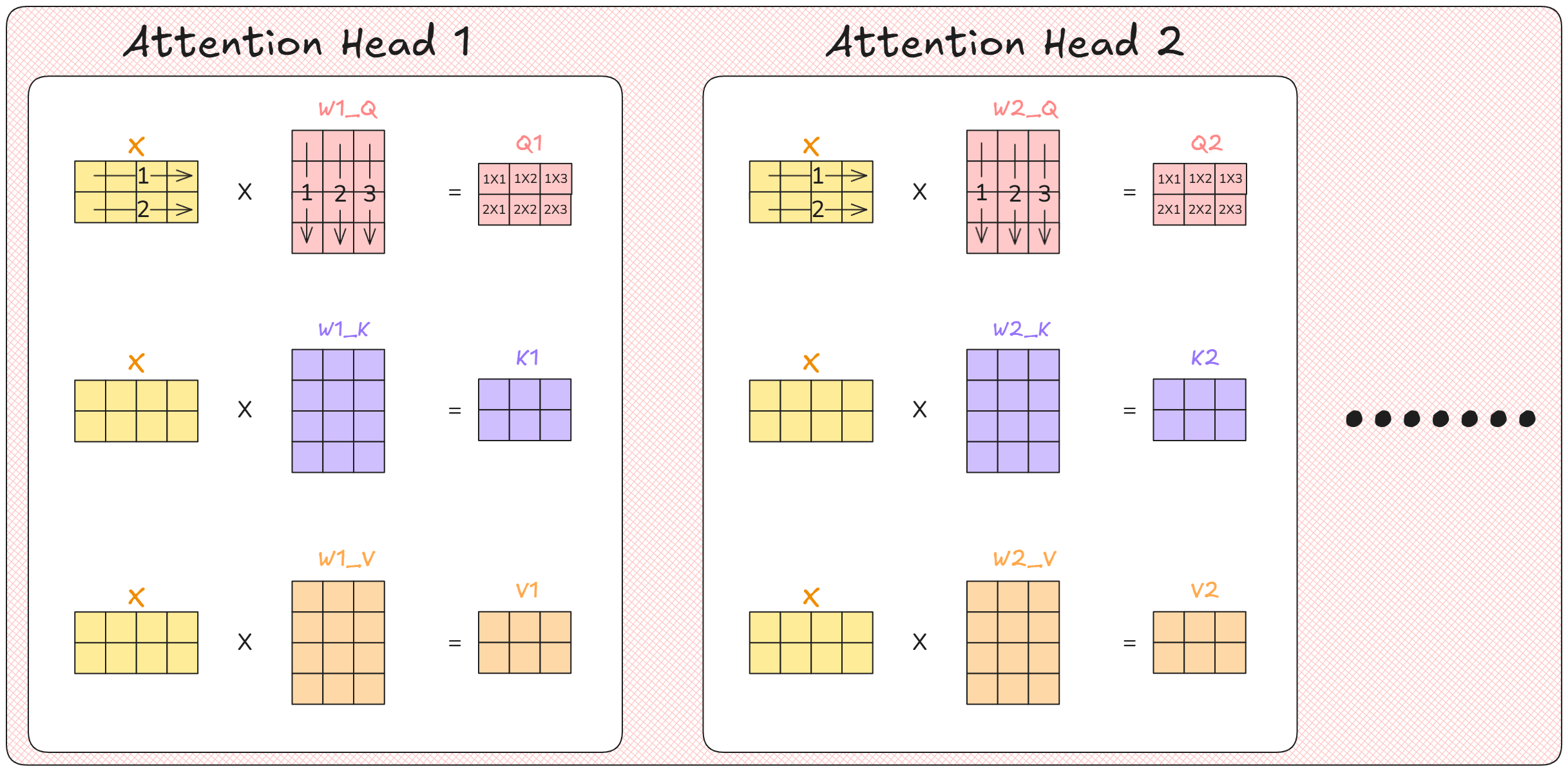
Third repeat the steps for each attention head
This is the how the output from each attention head will look like
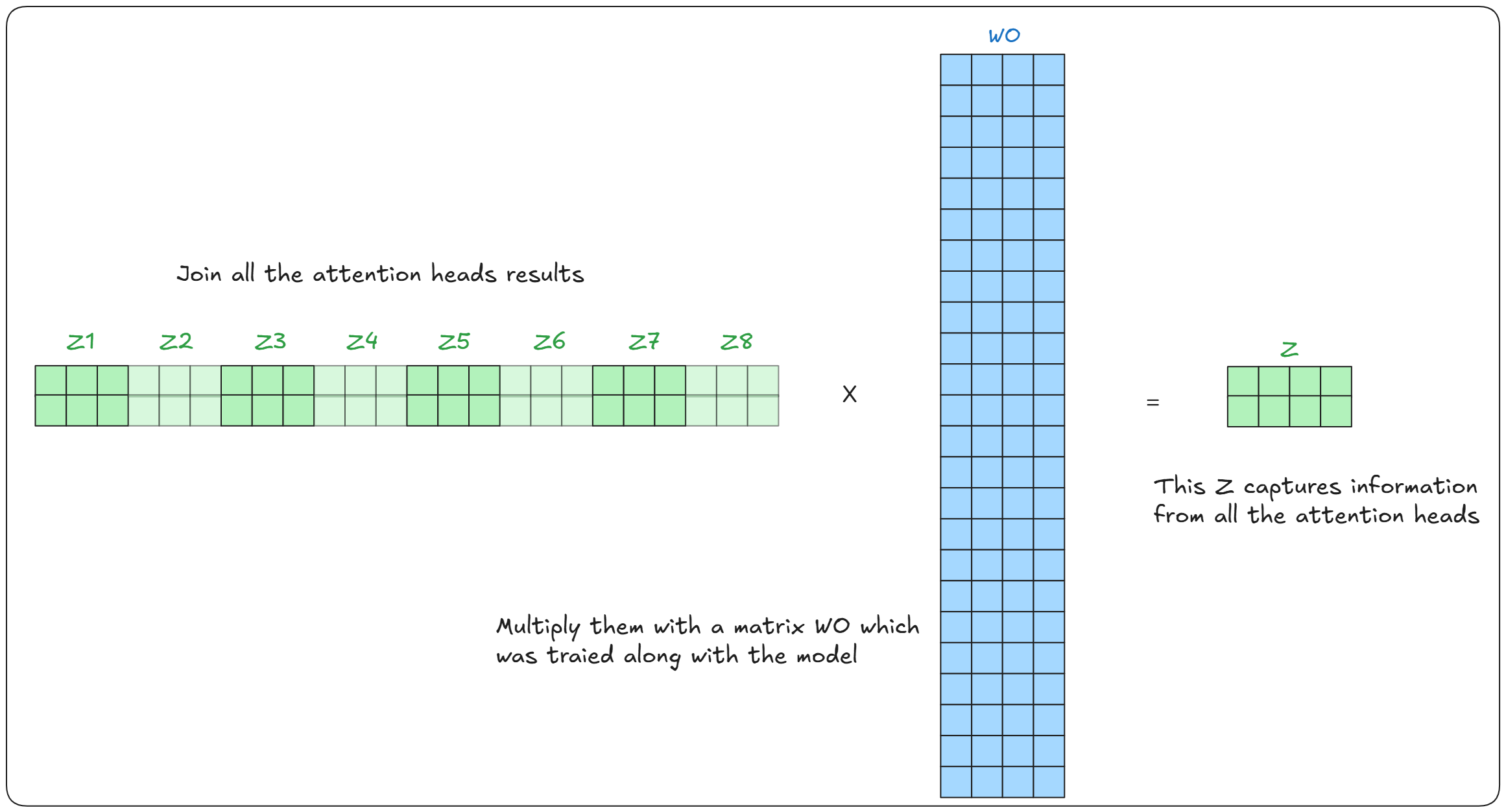
Finally join the outputs from all the attention head and multiply it with a matrix WO (which is trained along with the model) To get the final attention score
Here is a summary of everything that is going on
Let us now understand why this even works:
Forget about multi-head attention, attention blocks and all the JARGON.
Imagine you are at point A and want to go to B in a huge city.
Do you think there is only one path to go there? Of course not, there are thousands of way to reach that point.
But you will never know the best path, till you have tried a lot of them. More the better.
Hence a single matrix multiplication does not get you the best representation of query and key
Multiple queries can be made, multiple keys can be done for each of these query
That is the reason we do so many matrix multiplications - to try and get the best key for a query that is relevant to the question asked by the user
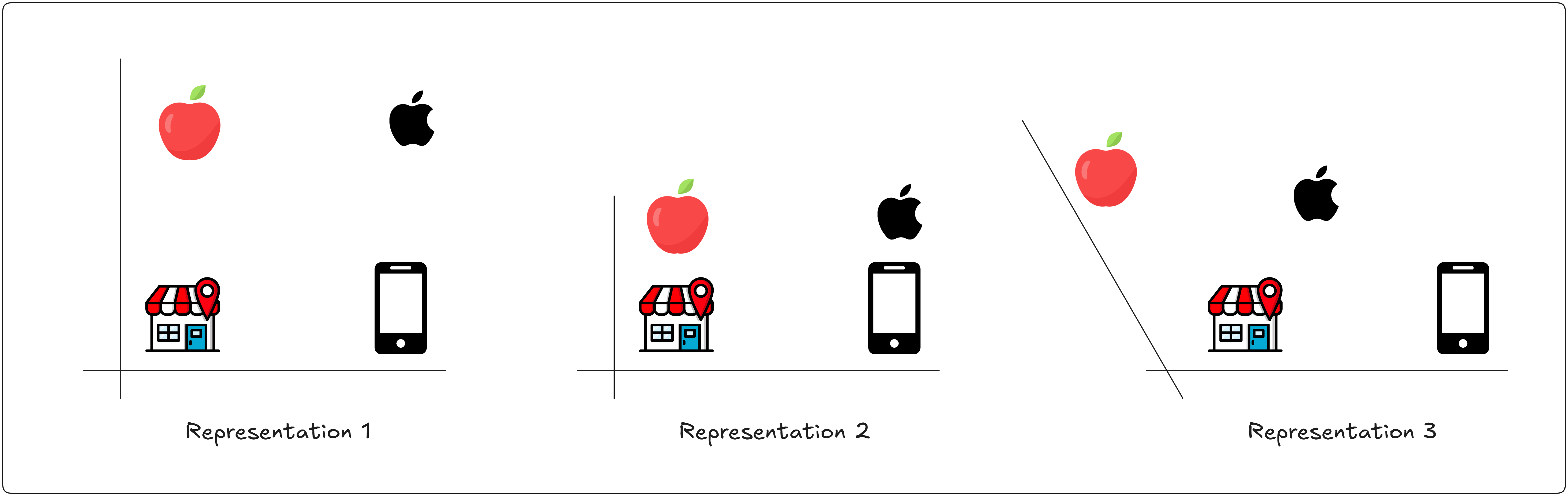
To visualize how Self-Attention creates different representation. Let’s have a look at the three different representation of different words “apple”,”market” & “cellphone”
Which of these representation is best to answer the following question
- What does the company apple make?
Representation 2 will be best to choose for this question, and it gives us the answer “cellphone” as that is the one closest to it.
What about the next question
- Where can I get a new iphone?
In this case Representation 3 will be the best option, and we will get the answer “market”.
(These are linear transformation and can be applied to any matrix, the 3rd one is called a shear operation)
Understanding Positional Encoding
Here is a video with more visualization as well as deep dive in RoPE
To understand What is Positional Encoding and why we need it, let’s imagine the scenario in which we do not have it.
First an input sentence, for E.g “Pramod likes to eat pizza with his friends”. Will be broken down into the respective words*
“Pramod”,”likes”,”to”,”eat”,”pizza”,”with”,”his”,”friends”
Second, Each word will be converted into an embedding of a given dimension.
Now, without Positional Encoding. The model has no information about the relative positioning of the words. (As everything is taken at once in parallel)
So the sentence is no different from “Pramod likes to eat friends with his pizza” or any other permutation of the word.
Hence, the reason we need PE (Positional Encoding) is to tell the model about the positions of different words relative to each other.
Now, what will be the preferred characteristics of such a PE:
- Unique encoding for each position: Because otherwise it will keep changing for different length of sentences. Position 2 for a 10 word sentence will be different than for a 100 word sentence. This will hamper training as there is no predictable pattern that can be followed.
- Linear relation between two encoded positions: If I know the position p of one word, it should be easy to calculate the position p+k of another word. This will make it easier for the model to learn the patter.
- Generalizes to longer sequences than those encountered in training: If the model is limited by the length of the sentences used in training, it will never work in the real world.
- Generated by a deterministic process the model can learn: It should be a simple formula, or easily calculable algorithm. To help our model generalize better.
- Extensible to multiple dimensions: Different scenarios can have different dimensions, we want it to work in all cases.
Integer Encoding
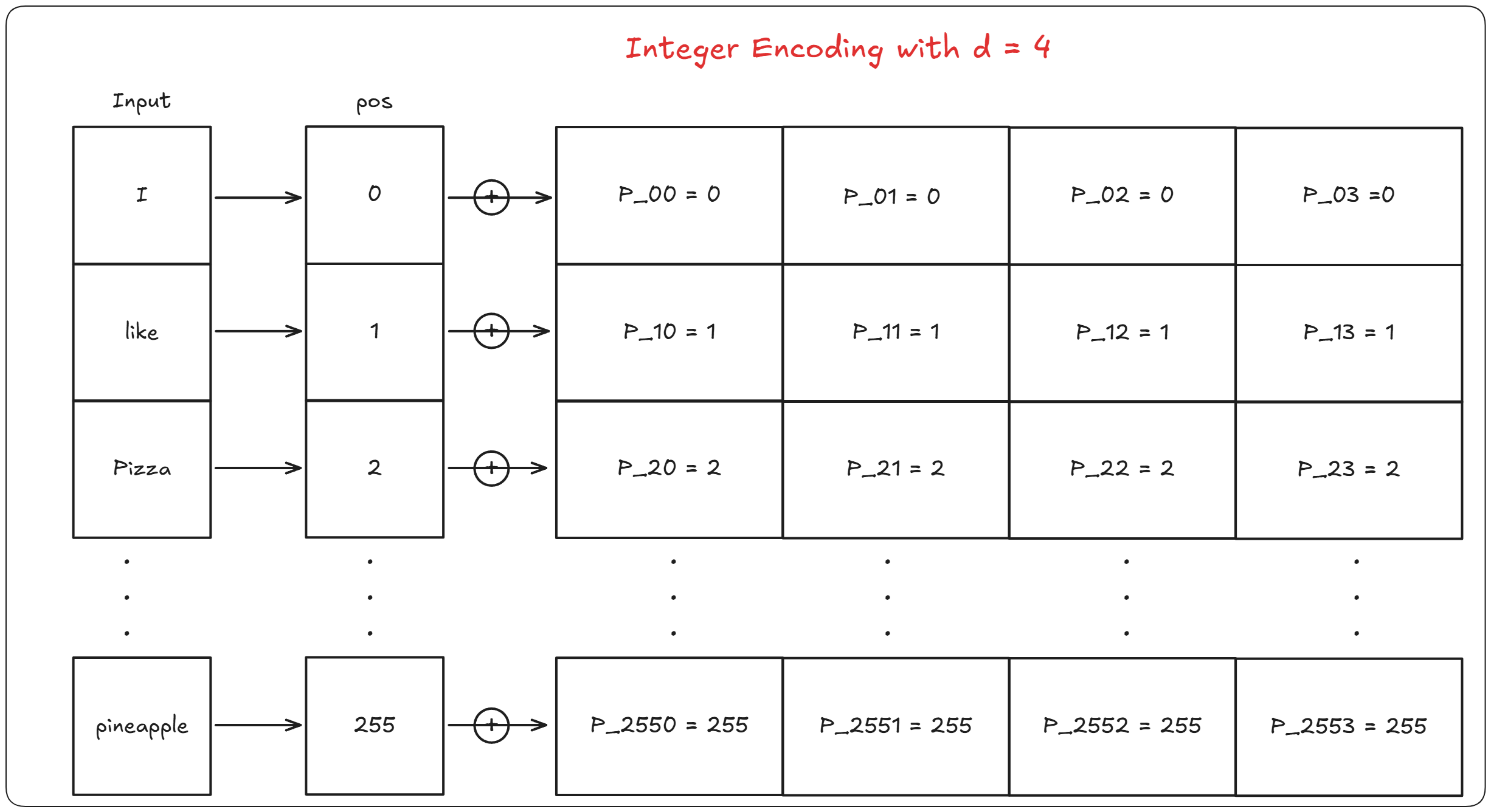
Reading the above conditions the first thought that will come to anyone’s mind will be. “Why not just add the position of the word” This naive solution will work for small sentences. But for longer sentences like lets say for some essay with 2000 words, adding position 2000 can lead to exploding or vanishing gradients.
There are other alternatives as well, Normalizing the integer encoding, binary encoding. But each has its own problems. To read more on detail go here.
Sinusoidal Encoding
One of the encoding methods that satisfies all our conditions is using sinusoidal functions, as done in the paper.
But why use cosine alternatively if sine satisfies all the conditions?
In reality, sine alone doesn’t satisfy all our requirements. While it meets most conditions, it fails to establish the linear relationship we need. Adding cosine functions complements sine’s limitations, creating a complete positional encoding system. Let me present a simple proof from here
Consider a sequence of sine and cosine pairs, each associated with a frequency $\omega_i$. Our goal is to find a linear transformation matrix $\mathbf{M}$ that can shift these sinusoidal functions by a fixed offset $k$:
\[\mathbf{M} \cdot \begin{bmatrix} \sin(\omega_i p) \\ \cos(\omega_i p) \end{bmatrix} = \begin{bmatrix} \sin(\omega_i(p + k)) \\ \cos(\omega_i(p + k)) \end{bmatrix}\]The frequencies $\omega_i$ follow a geometric progression that decreases with dimension index $i$, defined as:
\[\omega_i = \frac{1}{10000^{2i/d}}\]To find this transformation matrix, we can express it as a general 2×2 matrix with unknown coefficients $u_1$, $v_1$, $u_2$, and $v_2$:
\[\begin{bmatrix} u_1 & v_1 \\ u_2 & v_2 \end{bmatrix} \cdot \begin{bmatrix} \sin(\omega_i p) \\ \cos(\omega_i p) \end{bmatrix} = \begin{bmatrix} \sin(\omega_i(p + k)) \\ \cos(\omega_i(p + k)) \end{bmatrix}\]By applying the trigonometric addition theorem to the right-hand side, we can expand this into:
\[\begin{bmatrix} u_1 & v_1 \\ u_2 & v_2 \end{bmatrix} \cdot \begin{bmatrix} \sin(\omega_i p) \\ \cos(\omega_i p) \end{bmatrix} = \begin{bmatrix} \sin(\omega_i p)\cos(\omega_i k) + \cos(\omega_i p)\sin(\omega_i k) \\ \cos(\omega_i p)\cos(\omega_i k) - \sin(\omega_i p)\sin(\omega_i k) \end{bmatrix}\]This expansion gives us a system of two equations by matching coefficients:
\[u_1\sin(\omega_i p) + v_1\cos(\omega_i p) = \cos(\omega_i k)\sin(\omega_i p) + \sin(\omega_i k)\cos(\omega_i p)\] \[u_2\sin(\omega_i p) + v_2\cos(\omega_i p) = -\sin(\omega_i k)\sin(\omega_i p) + \cos(\omega_i k)\cos(\omega_i p)\]By comparing terms with $\sin(\omega_i p)$ and $\cos(\omega_i p)$ on both sides, we can solve for the unknown coefficients:
\[\begin{aligned} u_1 &= \cos(\omega_i k) & v_1 &= \sin(\omega_i k) \\ u_2 &= -\sin(\omega_i k) & v_2 &= \cos(\omega_i k) \end{aligned}\]These solutions give us our final transformation matrix $\mathbf{M}_k$:
\[\mathbf{M}_k = \begin{bmatrix} \cos(\omega_i k) & \sin(\omega_i k) \\ -\sin(\omega_i k) & \cos(\omega_i k) \end{bmatrix}\]Now that we understand what PE is and why we use sine and cosine functions, let us understand how it works.
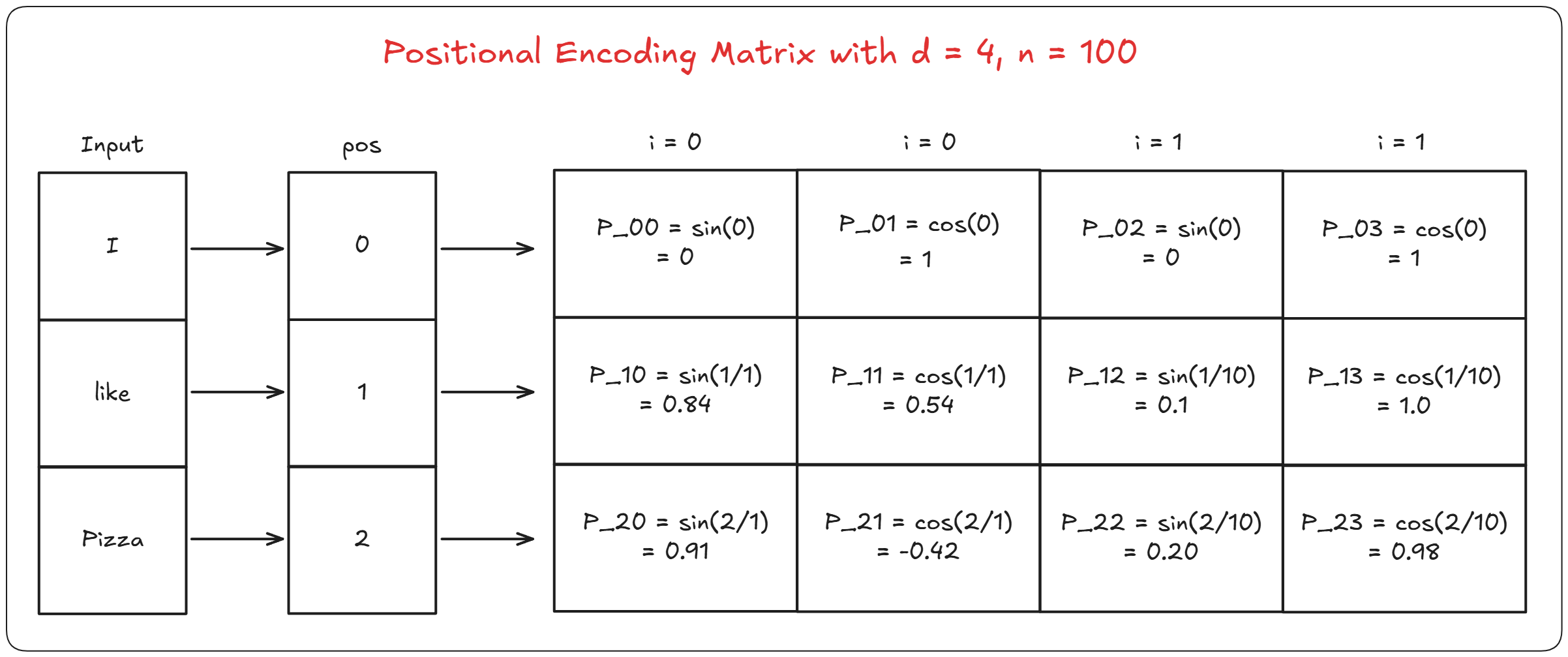
\(PE_{(pos,2i)} = \sin\left(\frac{pos}{10000^{2i/d_{model}}}\right)\) \(PE_{(pos,2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{model}}}\right)\)
pos = position of the word in the sentence (“Pramod likes pizza” Pramod is at position 0, likes in 1 and so on)
i = value for ith and (i+1)th index of the embedding, sine for even column number cosine for odd column number (“Pramod” is converted into a vector of embedding. Which has different indexes)
d_model = dimension of the model (in our case it is 512)
10,000 (n) = this is a constant determined experimentally
As you can see, using this we can calculate the PE value for each position and all the indexes for that position. Here is a simple illustration showing how its done.
Now expanding on the above this is how it looks like for the function
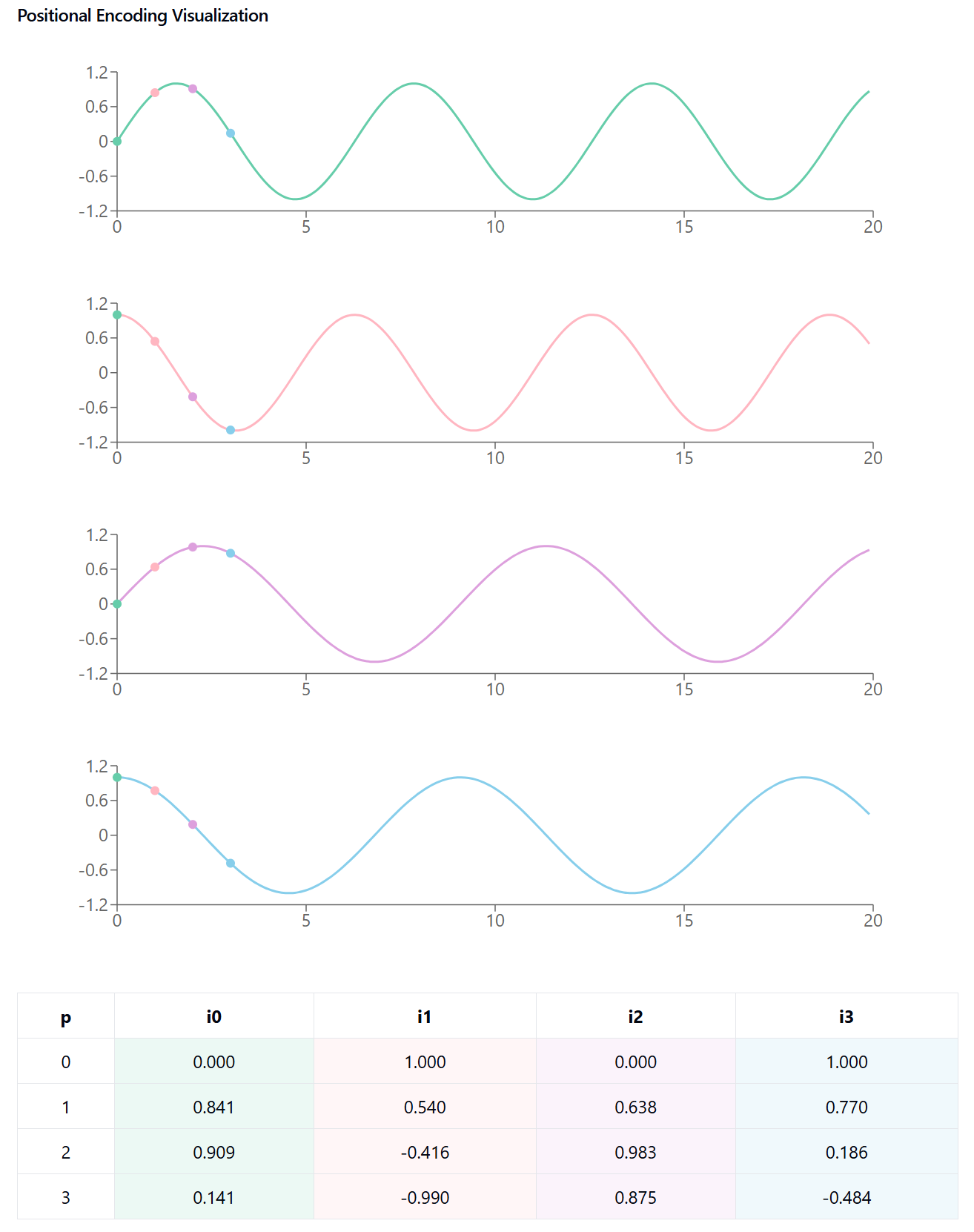 Visualization inspired by this fantastic blog
Visualization inspired by this fantastic blog
This is how it looks like for the original with n = 10,000, d_model = 10,000 and sequence length=100 Code to generate here
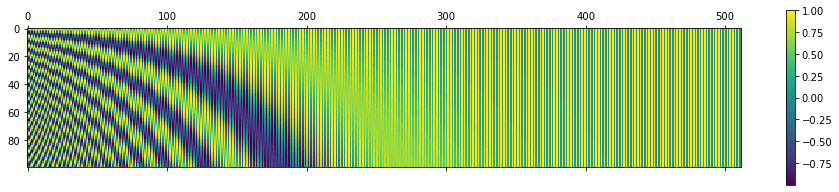
Imagine it as such: each index on the y axis represents a word, and everything corresponding on the x axis to that index is its positional encoding.
Understanding The Encoder and Decoder Block
If everything so far has made sense, this is going to be a cake walk for you. Because this is where we put everything together.
A single transformer can have multiple encoder, as well as decoder blocks.
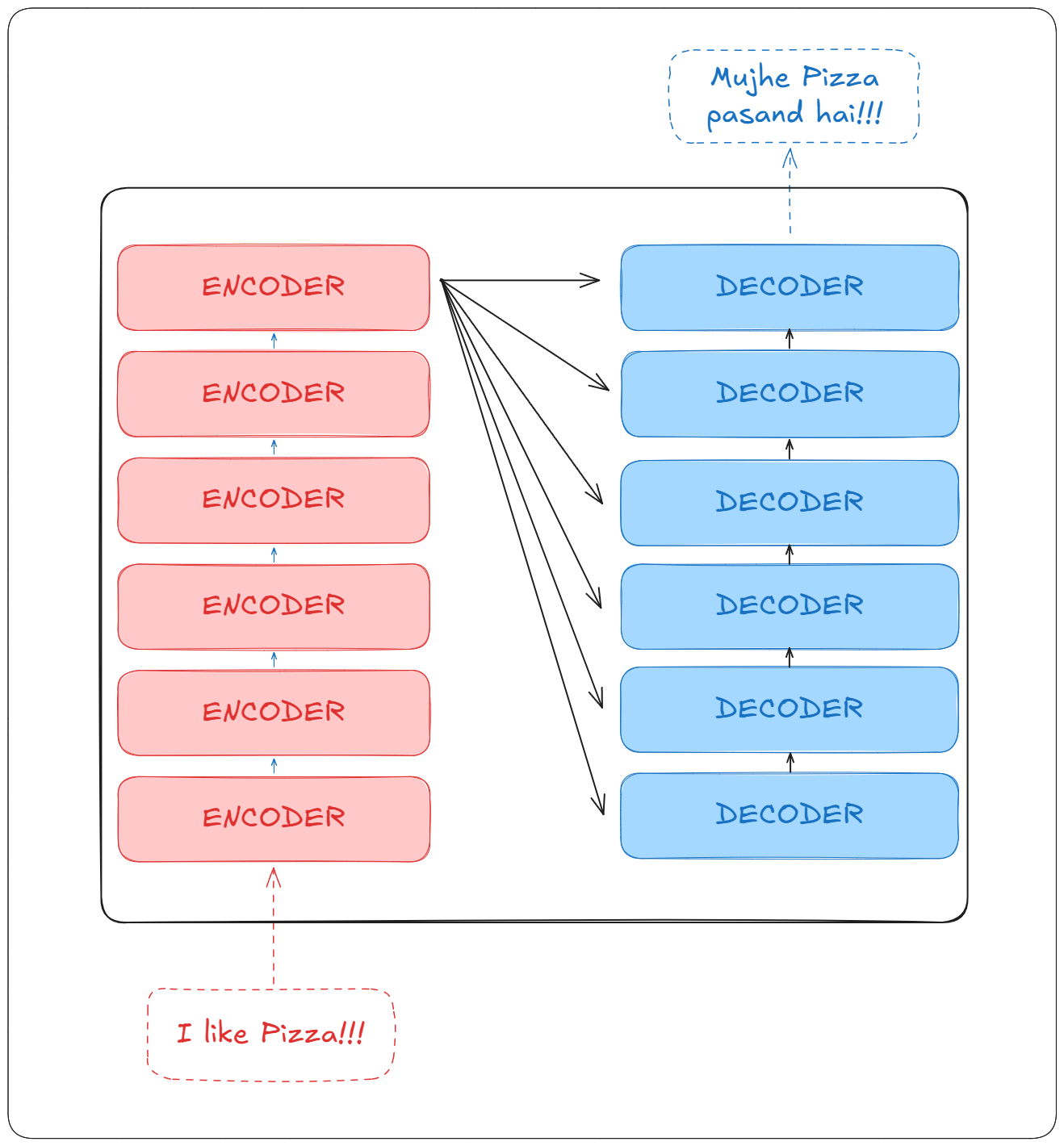
Encoder
Let’s start with the encoder part first.
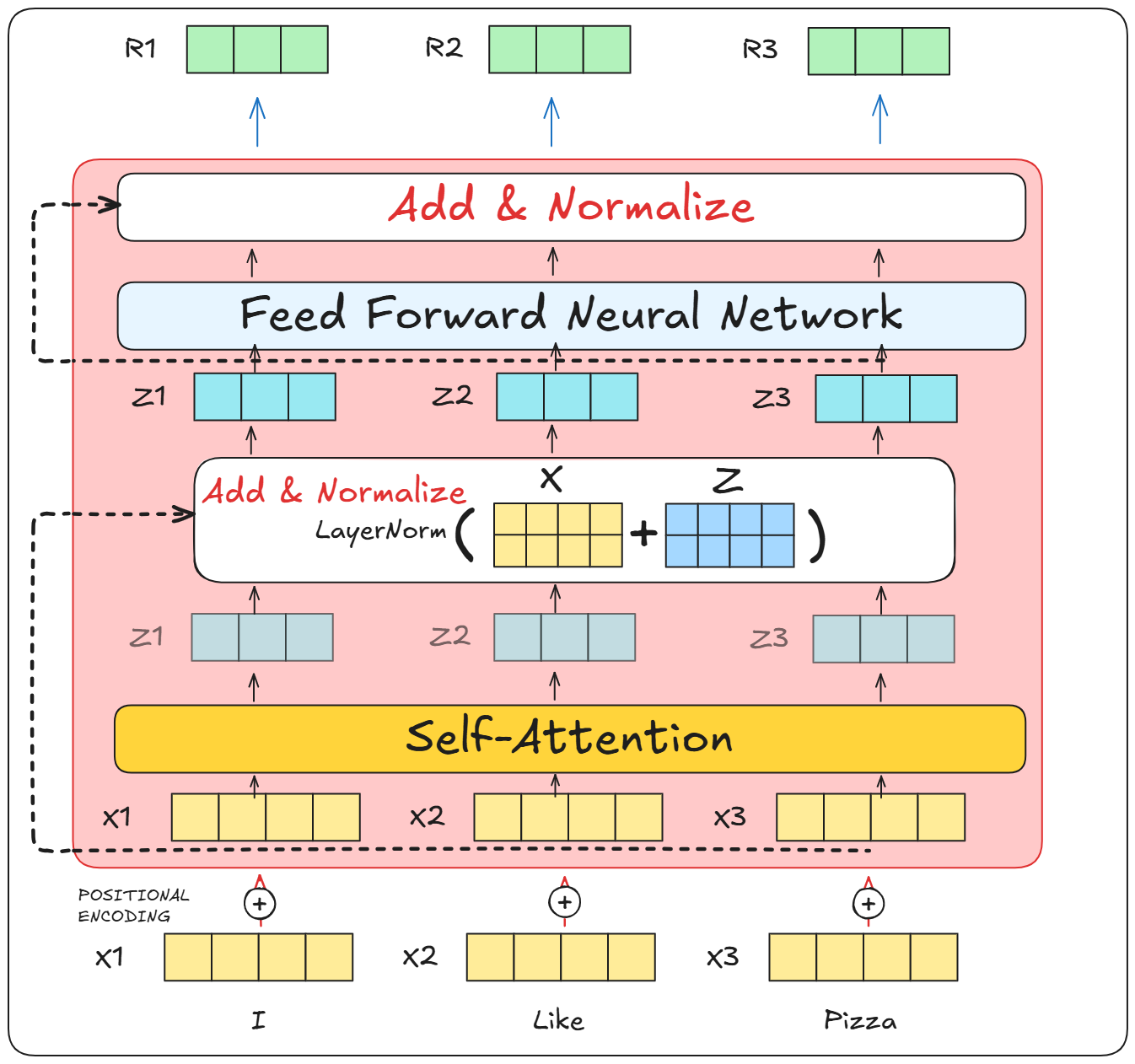
It consists of multiple encoders, and each encoder block consists of the following parts:
- Multi-head Attention
- Residual connection
- Layer Normalization
- Feed Forward network
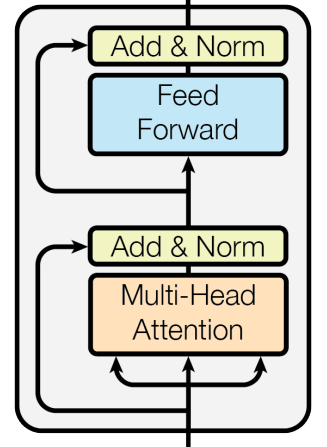
Residual connection
We have already talked about Multi-head attention in great detail so let’s talk about the remaining three.
Residual connection or also known as skip connections, they work as the name applies. They take the input and skip it over a block and take it to the next block.
Layer Normalization
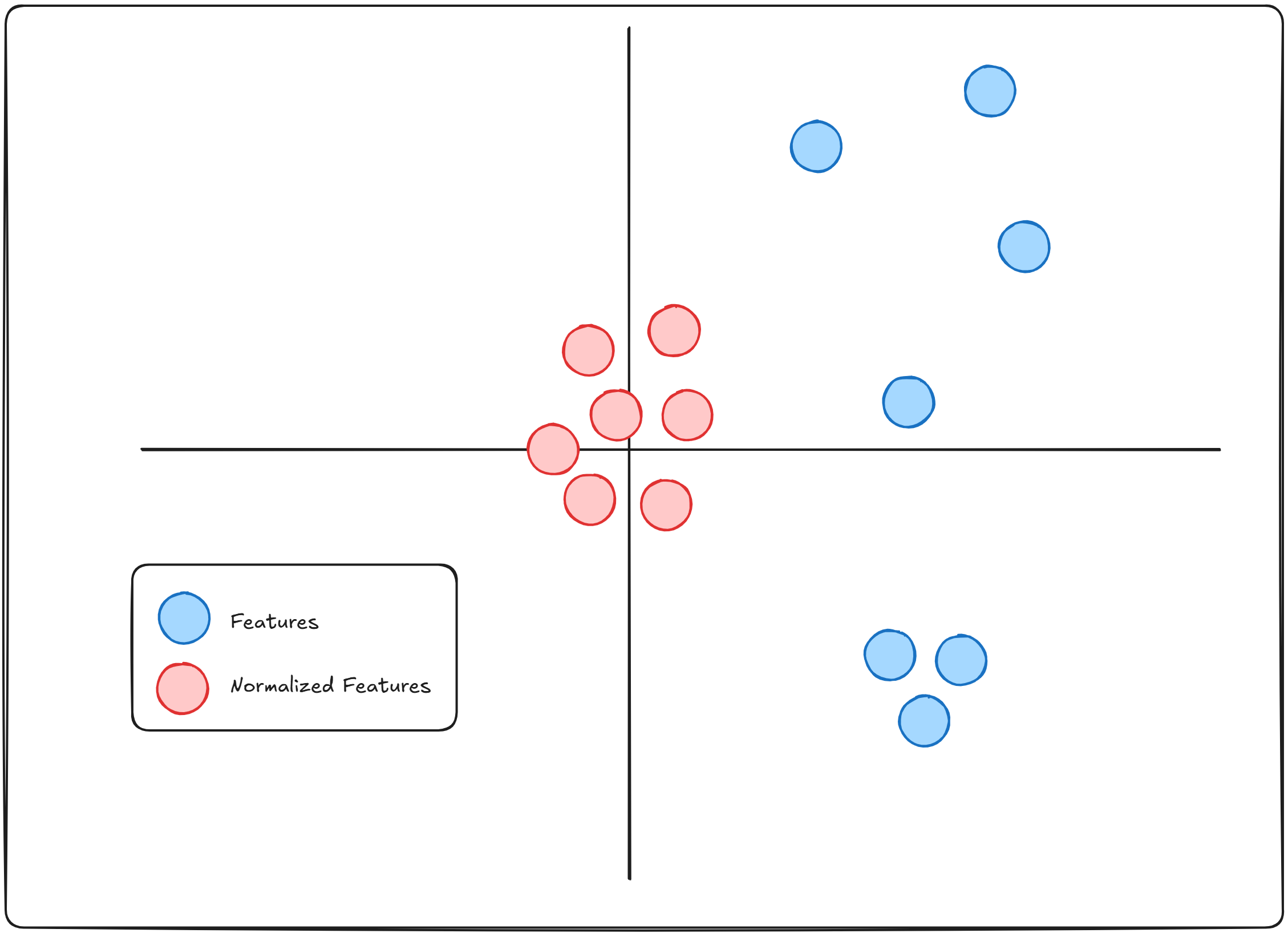
Layer normalization was a development after batch normalization. Before we talk about either of these, we have to understand what normalization is.
Normalization is a method to bring different features in the same scale, This is done to stabilize training. Because when models try to learn from features with drastically different scales, it can slow down training as well as cause exploding gradients. (Read more here)
Batch normalization is the method where the mean and standard deviation of an entire batch is subtracted from the future layer.
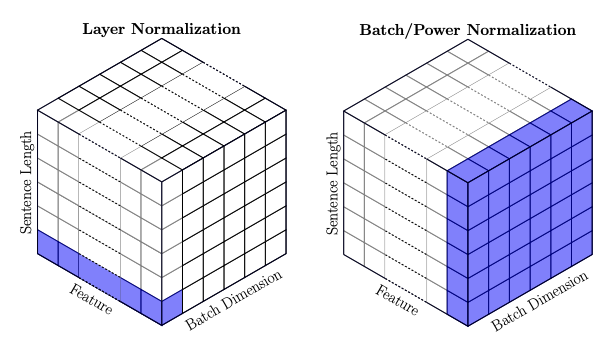 (image taken from this stackexchange)
(image taken from this stackexchange)
In Layer normalization, instead of focusing on the entire batch, all the features of a single instance are focused on.
Think of it like this, we take each word from a sentence, and normalize that word.
To get a better grasp, consider reading this blog
Feed Forward network
The Feed Forward network (FFN) is added to introduce non-linearity and complexity to the model. While the attention mechanism is great at capturing relationships between different positions in the sequence, It is inherently still a linear operation (as mentioned earlier).
The FFN adds non-linearity through its activation functions (typically ReLU), allowing the model to learn more complex patterns and transformations that pure attention alone cannot capture.
Imagine it this way: if the attention mechanism is like having a conversation where everyone can talk to everyone else (global interaction), the FFN is like giving each person time to think deeply about what they’ve heard and process it independently (local processing). Both are necessary for effective understanding and transformation of the input. Without the FFN, transformers would be severely limited in their ability to learn complex functions and would essentially be restricted to weighted averaging operations through attention mechanisms alone.
Decoder Block
The output of the encoder is fed into each decoder block as Key and Value matrices during data processing. The decoder block is auto-regressive. Meaning it outputs one after the other and takes its own output as an input.
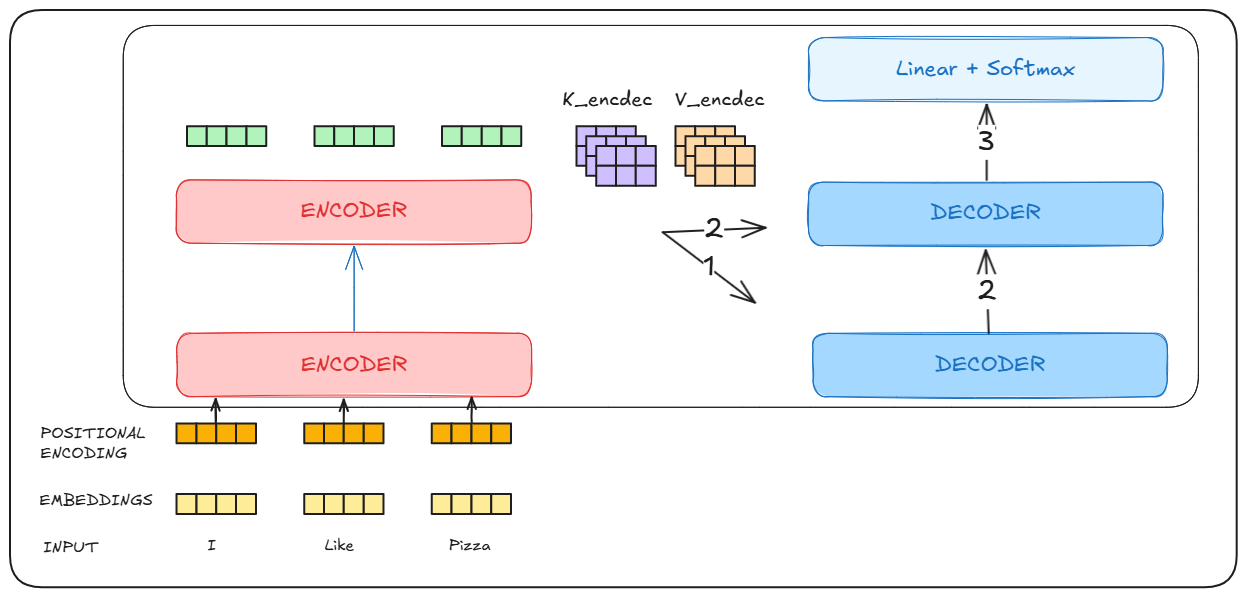
- The decoder block takes the Keys and Values from the encoder and creates it own queries from the previous output.
- Using the output of one, it moves to step 2, where the output from the previous decoder block is taken as the query and key, value is taken from the encoder.
- This repeats till we get an output from the decoder, which it takes as the input for creating the next token
- This repeats till we reach
token
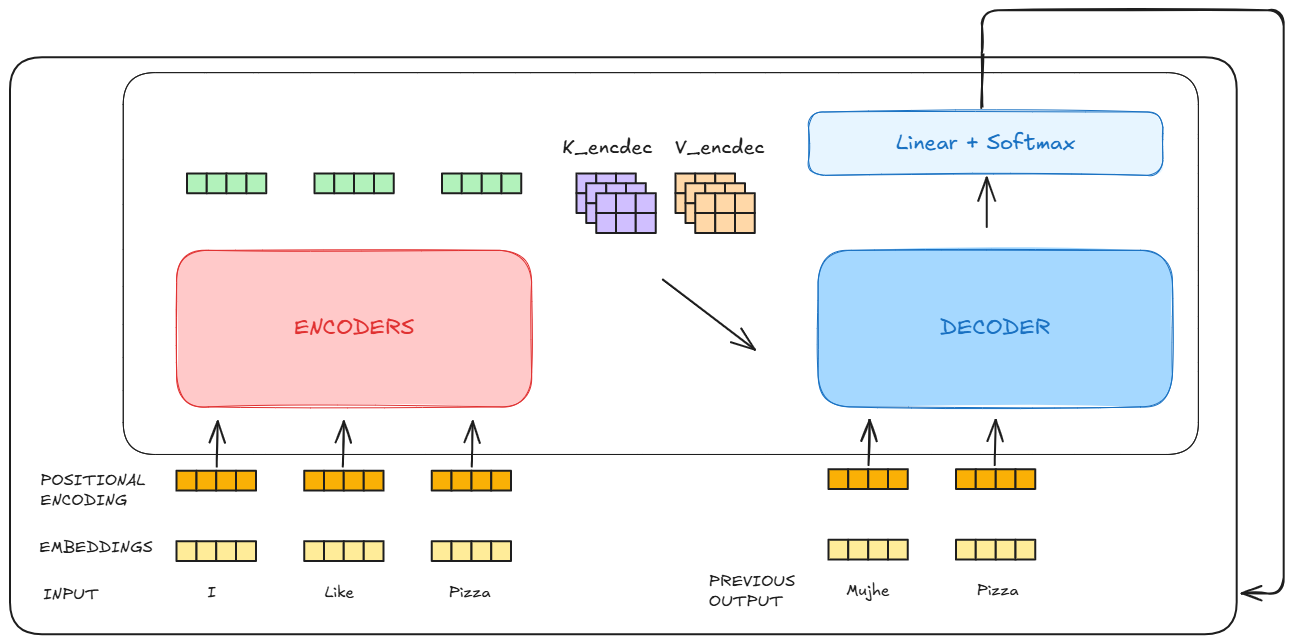
There is also a slight variation in the decoder block, As in it we apply a mask to let the self-attention mechanism only attend to earlier positions in the output sequence.
That is all the high level understanding you need to have, to be able to write a transformer of your own. Now let us look at the paper as well as the code
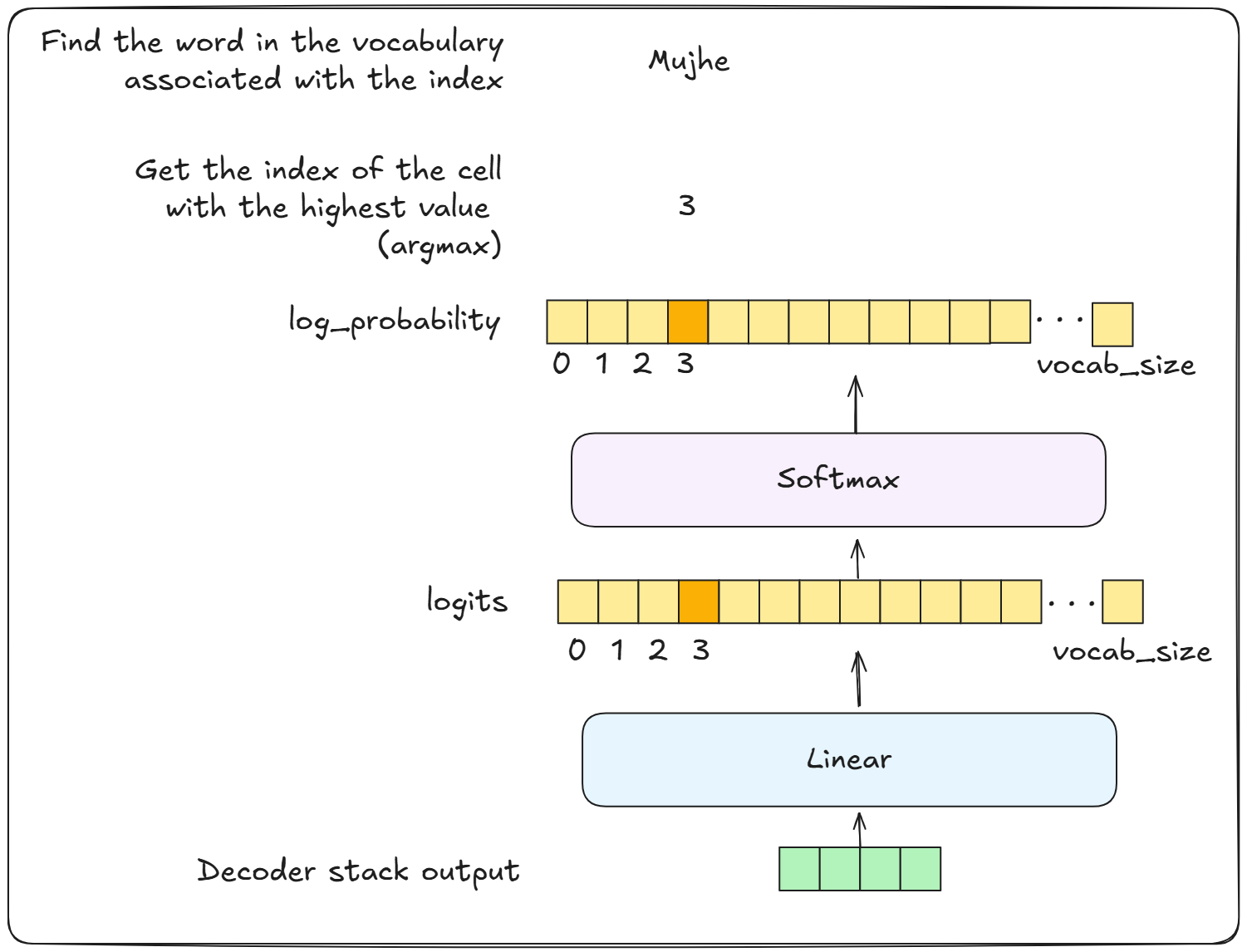
Final linear & Softmax layer
The decoder gives out a vector of numbers (floating point generally), which is sent to a linear layer.
The linear layer outputs the score for each word in the vocabulary (the amount of unique words in the training dataset)
Which is then sent to the softmax layer, which converts these scores into probabilities. And the word with the highest probability is given out. (This is usually the case, sometimes we can set it so that we get the 2nd most probable word, or the 3rd most and so on)
Coding the transformer
For the following section I will recommend you have 3 tabs open. This blog, a jupyter notebook and the original paper
Abstract & Introduction
This section brings you up to speed about what the paper is about and why it was made in the first place.
There are some concepts that can help you learn new things, RNNs, Convolution neural network and about BLEU.
Also it is important to know that transformers were originally created for text to text translation. I.E from one language to another.
Hence they have an encoder section and a decoder section. They pass around information and it is known as cross attention (more on the difference between self-attention and cross attention later)
Background
This section usually talks about the work done previously in the field, known issues and what people have used to fix them. One very important thing for us to understand to keep in mind is.
“Keeping track of distant information”. Transformers are amazing for a multitude of reasons, but one key advantage is that they can remember distant relations.
Solutions like RNNs and LSTMs lose the contextual meaning as the sentence gets longer. But transformers do not run into such problem. (A problem tho, hopefully none existent when you read it is. The context window length. This fixes how much information the transformer can see)
Model Architecture
The section all of us had been waiting for. I will divert a bit from the paper here. Because I find it easier to follow the data. Also if you read the paper, each word of it should make sense to you.
We will first start with the Multi-Head Attention, then the feed forward network, followed by the positional encoding, Using these we will finish the Encoder Layer, subsequently we will move to the Decoder Layer, After which we will write the Encoder & Decoder block, and finally end it with writing the training loop for an entire Transformer on real world data.
The full notebook can be found here

Necessary imports
import math
import torch
import torch.nn as nn
from torch.nn.functional import softmax
Multi-Head Attention
By now you should have good grasp of how attention works, so let us first start with coding the scaled dot-product attention (as MHA is basically multiple scaled dot-product stacked together). Reference section is 3.2.1 Scaled Dot-Product Attention
# try to finish this function on your own
def scaled_dot_product_attention(query, key, value, mask=None):
"""
Args:
query: (batch_size, num_heads, seq_len_q, d_k)
key: (batch_size, num_heads, seq_len_k, d_k)
value: (batch_size, num_heads, seq_len_v, d_v)
mask: Optional mask to prevent attention to certain positions
"""
# get the size of d_k using the query or the key
# calculate the attention score using the formula given. Be vary of the dimension of Q and K. And what you need to transpose to achieve the desired results.
#YOUR CODE HERE
# hint 1: batch_size and num_heads should not change
# hint 2: nXm @ mXn -> nXn, but you cannot do nXm @ nXm, the right dimension of the left matrix should match the left dimension of the right matrix. The easy way I visualize it is as, who face each other must be same
# add inf is a mask is given, This is used for the decoder layer. You can use help for this if you want to. I did!!
#YOUR CODE HERE
# get the attention weights by taking a softmax on the scores, again be wary of the dimensions. You do not want to take softmax of batch_size or num_heads. Only of the values. How can you do that?
#YOUR CODE HERE
# return the attention by multiplying the attention weights with the Value (V)
#YOUR CODE HERE
# my implementation
def scaled_dot_product_attention(query, key, value, mask=None):
"""
Args:
query: (batch_size, num_heads, seq_len_q, d_k)
key: (batch_size, num_heads, seq_len_k, d_k)
value: (batch_size, num_heads, seq_len_v, d_v)
mask: Optional mask to prevent attention to certain positions
"""
# Shape checks
assert query.dim() == 4, f"Query should be 4-dim but got {query.dim()}-dim"
assert key.size(-1) == query.size(-1), "Key and query depth must be equal"
assert key.size(-2) == value.size(-2), "Key and value sequence length must be equal"
d_k = query.size(-1)
# Attention scores
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
attention_weights = softmax(scores, dim=-1)
return torch.matmul(attention_weights, value)
Using this let us complete the MHA, Section 3.2.2
class MultiHeadAttention(nn.Module):
#Let me write the initializer just for this class, so you get an idea of how it needs to be done
def __init__(self, d_model, num_heads):
super().__init__()
assert d_model % num_heads == 0, "d_model must be divisible by num_heads" #think why?
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads # Note: use integer division //
# Create the learnable projection matrices
self.W_q = nn.Linear(d_model, d_model) #think why we are doing from d_model -> d_model
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
@staticmethod
def scaled_dot_product_attention(query, key, value, mask=None):
#YOUR IMPLEMENTATION HERE
def forward(self, query, key, value, mask=None):
#get batch_size and sequence length
#YOUR CODE HERE
# 1. Linear projections
#YOUR CODE HERE
# 2. Split into heads
#YOUR CODE HERE
# 3. Apply attention
#YOUR CODE HERE
# 4. Concatenate heads
#YOUR CODE HERE
# 5. Final projection
#YOUR CODE HERE
- I had a hard time understanding the difference between view and transpose. These 2 links should help you out, When to use view,transpose & permute and Difference between view & transpose
- Contiguous and view, still eluded me. Till I read these, Pytorch Internals and Contiguous & Non-Contiguous Tensor
- Linear
- I also have a post talking about how the internal memory management of tensors work, read this if you are interested.
#my implementation
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads # Note: use integer division //
# Create the learnable projection matrices
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
@staticmethod
def scaled_dot_product_attention(query, key, value, mask=None):
"""
Args:
query: (batch_size, num_heads, seq_len_q, d_k)
key: (batch_size, num_heads, seq_len_k, d_k)
value: (batch_size, num_heads, seq_len_v, d_v)
mask: Optional mask to prevent attention to certain positions
"""
# Shape checks
assert query.dim() == 4, f"Query should be 4-dim but got {query.dim()}-dim"
assert key.size(-1) == query.size(-1), "Key and query depth must be equal"
assert key.size(-2) == value.size(-2), "Key and value sequence length must be equal"
d_k = query.size(-1)
# Attention scores
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
attention_weights = softmax(scores, dim=-1)
return torch.matmul(attention_weights, value)
def forward(self, query, key, value, mask=None):
batch_size = query.size(0)
seq_len = query.size(1)
# 1. Linear projections
Q = self.W_q(query) # (batch_size, seq_len, d_model)
K = self.W_k(key)
V = self.W_v(value)
# 2. Split into heads
Q = Q.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
K = K.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
V = V.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
# 3. Apply attention
output = self.scaled_dot_product_attention(Q, K, V, mask)
# 4. Concatenate heads
output = output.transpose(1, 2).contiguous().view(batch_size, seq_len, self.d_model)
# 5. Final projection
return self.W_o(output)
Feed Forward Network
{explain “Another way of describing this is as two convolutions with kernel size 1. The dimensionality of input and output is dmodel = 512, and the inner-layer has dimensionality df f = 2048. “}
Section 3.3
class FeedForwardNetwork(nn.Module):
"""Position-wise Feed-Forward Network
Args:
d_model: input/output dimension
d_ff: hidden dimension
dropout: dropout rate (default=0.1)
"""
def __init__(self, d_model, d_ff, dropout=0.1):
super().__init__()
#create a sequential ff model as mentioned in section 3.3
#YOUR CODE HERE
def forward(self, x):
"""
Args:
x: Input tensor of shape (batch_size, seq_len, d_model)
Returns:
Output tensor of shape (batch_size, seq_len, d_model)
"""
#YOUR CODE HERE
#my implementation
class FeedForwardNetwork(nn.Module):
"""Position-wise Feed-Forward Network
Args:
d_model: input/output dimension
d_ff: hidden dimension
dropout: dropout rate (default=0.1)
"""
def __init__(self, d_model, d_ff, dropout=0.1):
super().__init__()
self.model = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(d_ff, d_model),
nn.Dropout(dropout)
)
def forward(self, x):
"""
Args:
x: Input tensor of shape (batch_size, seq_len, d_model)
Returns:
Output tensor of shape (batch_size, seq_len, d_model)
"""
return self.model(x)
Positional Encoding
Section 3.5
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_length=5000):
super().__init__()
# Create matrix of shape (max_seq_length, d_model)
#YOUR CODE HERE
# Create position vector
#YOUR CODE HERE
# Create division term
#YOUR CODE HERE
# Compute positional encodings
#YOUR CODE HERE
# Register buffer
#YOUR CODE HERE
def forward(self, x):
"""
Args:
x: Tensor shape (batch_size, seq_len, d_model)
"""
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_length=5000):
super().__init__()
# Create matrix of shape (max_seq_length, d_model)
pe = torch.zeros(max_seq_length, d_model)
# Create position vector
position = torch.arange(0, max_seq_length).unsqueeze(1) # Shape: (max_seq_length, 1)
# Create division term
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
# Compute positional encodings
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
# Register buffer
self.register_buffer('pe', pe.unsqueeze(0)) # Shape: (1, max_seq_length, d_model)
def forward(self, x):
"""
Args:
x: Tensor shape (batch_size, seq_len, d_model)
"""
return x + self.pe[:, :x.size(1)] # Add positional encoding up to sequence length
Encoder Layer
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super().__init__()
# 1. Multi-head attention
#YOUR CODE HERE
# 2. Layer normalization
#YOUR CODE HERE
# 3. Feed forward
#YOUR CODE HERE
# 4. Another layer normalization
#YOUR CODE HERE
# 5. Dropout
#YOUR CODE HERE
def forward(self, x, mask=None):
"""
Args:
x: Input tensor of shape (batch_size, seq_len, d_model)
mask: Optional mask for padding
Returns:
x: Output tensor of shape (batch_size, seq_len, d_model)
"""
# 1. Multi-head attention with residual connection and layer norm
#YOUR CODE HERE
# 2. Feed forward with residual connection and layer norm
#YOUR CODE HERE
return x
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super().__init__()
# 1. Multi-head attention
self.mha = MultiHeadAttention(d_model,num_heads)
# 2. Layer normalization
self.layer_norm_1 = nn.LayerNorm(d_model)
# 3. Feed forward
self.ff = FeedForwardNetwork(d_model,d_ff)
# 4. Another layer normalization
self.layer_norm_2 = nn.LayerNorm(d_model)
# 5. Dropout
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask=None):
"""
Args:
x: Input tensor of shape (batch_size, seq_len, d_model)
mask: Optional mask for padding
Returns:
x: Output tensor of shape (batch_size, seq_len, d_model)
"""
# 1. Multi-head attention with residual connection and layer norm
# att_output = self.attention(...)
# x = x + att_output # residual connection
# x = self.norm1(x) # layer normalization
att_output = self.mha(x, x, x, mask)
x = self.dropout(x + att_output) # Apply dropout after residual
x = self.layer_norm_1(x)
ff_output = self.ff(x)
x = self.dropout(x + ff_output) # Apply dropout after residual
x = self.layer_norm_2(x)
# 2. Feed forward with residual connection and layer norm
return x
Decoder Layer
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super().__init__()
# 1. Masked Multi-head attention
#YOUR CODE HERE
# 2. Layer norm for first sub-layer
#YOUR CODE HERE
# 3. Multi-head attention for cross attention with encoder output
# This will take encoder output as key and value
#YOUR CODE HERE
# 4. Layer norm for second sub-layer
#YOUR CODE HERE
# 5. Feed forward network
#YOUR CODE HERE
# 6. Layer norm for third sub-layer
#YOUR CODE HERE
# 7. Dropout
#YOUR CODE HERE
def forward(self, x, encoder_output, src_mask=None, tgt_mask=None):
"""
Args:
x: Target sequence embedding (batch_size, target_seq_len, d_model)
encoder_output: Output from encoder (batch_size, source_seq_len, d_model)
src_mask: Mask for source padding
tgt_mask: Mask for target padding and future positions
"""
# 1. Masked self-attention
# Remember: In decoder self-attention, query, key, value are all x
#YOUR CODE HERE
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super().__init__()
# 1. Masked Multi-head attention
self.mha_1 = MultiHeadAttention(d_model,num_heads)
# 2. Layer norm for first sub-layer
self.layer_norm_1 = nn.LayerNorm(d_model)
# 3. Multi-head attention for cross attention with encoder output
# This will take encoder output as key and value
self.mha_2 = MultiHeadAttention(d_model,num_heads)
# 4. Layer norm for second sub-layer
self.layer_norm_2 = nn.LayerNorm(d_model)
# 5. Feed forward network
self.ff = FeedForwardNetwork(d_model,d_ff)
# 6. Layer norm for third sub-layer
self.layer_norm_3 = nn.LayerNorm(d_model)
# 7. Dropout
self.dropout = nn.Dropout(dropout)
def forward(self, x, encoder_output, src_mask=None, tgt_mask=None):
"""
Args:
x: Target sequence embedding (batch_size, target_seq_len, d_model)
encoder_output: Output from encoder (batch_size, source_seq_len, d_model)
src_mask: Mask for source padding
tgt_mask: Mask for target padding and future positions
"""
# 1. Masked self-attention
# Remember: In decoder self-attention, query, key, value are all x
att_output = self.mha_1(x,x,x,tgt_mask)
x = self.dropout(x + att_output)
x = self.layer_norm_1(x)
att_output_2 = self.mha_2(x, encoder_output,encoder_output, src_mask)
x = self.dropout(x + att_output_2)
x = self.layer_norm_2(x)
ff_output = self.ff(x)
x = self.dropout(x + ff_output)
x = self.layer_norm_3(x)
return x
Encoder
class Encoder(nn.Module):
def __init__(self,
vocab_size,
d_model,
num_layers=6,
num_heads=8,
d_ff=2048,
dropout=0.1,
max_seq_length=5000):
super().__init__()
# 1. Input embedding
#YOUR CODE HERE
# 2. Positional encoding
#YOUR CODE HERE
# 3. Dropout
#YOUR CODE HERE
# 4. Stack of N encoder layers
#YOUR CODE HERE
def forward(self, x, mask=None):
"""
Args:
x: Input tokens (batch_size, seq_len)
mask: Mask for padding positions
Returns:
encoder_output: (batch_size, seq_len, d_model)
"""
# 1. Pass through embedding layer and scale
#YOUR CODE HERE
# 2. Add positional encoding and apply dropout
#YOUR CODE HERE
# 3. Pass through each encoder layer
#YOUR CODE HERE
class Encoder(nn.Module):
def __init__(self,
vocab_size,
d_model,
num_layers=6,
num_heads=8,
d_ff=2048,
dropout=0.1,
max_seq_length=5000):
super().__init__()
# 1. Input embedding
self.embeddings = nn.Embedding(vocab_size, d_model)
self.scale = math.sqrt(d_model)
# 2. Positional encoding
self.pe = PositionalEncoding(d_model, max_seq_length)
# 3. Dropout
self.dropout = nn.Dropout(dropout)
# 4. Stack of N encoder layers
self.encoder_layers = nn.ModuleList([
EncoderLayer(d_model, num_heads, d_ff, dropout)
for _ in range(num_layers)
])
def forward(self, x, mask=None):
"""
Args:
x: Input tokens (batch_size, seq_len)
mask: Mask for padding positions
Returns:
encoder_output: (batch_size, seq_len, d_model)
"""
# 1. Pass through embedding layer and scale
x = self.embeddings(x) * self.scale
# 2. Add positional encoding and apply dropout
x = self.dropout(self.pe(x))
# 3. Pass through each encoder layer
for layer in self.encoder_layers:
x = layer(x, mask)
return x
Decoder
class Decoder(nn.Module):
def __init__(self,
vocab_size,
d_model,
num_layers=6,
num_heads=8,
d_ff=2048,
dropout=0.1,
max_seq_length=5000):
super().__init__()
# 1. Output embedding
#YOUR CODE HERE
# 2. Positional encoding
#YOUR CODE HERE
# 3. Dropout
#YOUR CODE HERE
# 4. Stack of N decoder layers
#YOUR CODE HERE
def forward(self, x, encoder_output, src_mask=None, tgt_mask=None):
"""
Args:
x: Target tokens (batch_size, target_seq_len)
encoder_output: Output from encoder (batch_size, source_seq_len, d_model)
src_mask: Mask for source padding
tgt_mask: Mask for target padding and future positions
Returns:
decoder_output: (batch_size, target_seq_len, d_model)
"""
# 1. Pass through embedding layer and scale
#YOUR CODE HERE
# 2. Add positional encoding and dropout
#YOUR CODE HERE
# 3. Pass through each decoder layer
#YOUR CODE HERE
class Decoder(nn.Module):
def __init__(self,
vocab_size,
d_model,
num_layers=6,
num_heads=8,
d_ff=2048,
dropout=0.1,
max_seq_length=5000):
super().__init__()
# 1. Output embedding
self.embeddings = nn.Embedding(vocab_size, d_model)
self.scale = math.sqrt(d_model)
# 2. Positional encoding
self.pe = PositionalEncoding(d_model, max_seq_length)
# 3. Dropout
self.dropout = nn.Dropout(dropout)
# 4. Stack of N decoder layers
self.decoder_layers = nn.ModuleList([
DecoderLayer(d_model, num_heads, d_ff, dropout)
for _ in range(num_layers)
])
def forward(self, x, encoder_output, src_mask=None, tgt_mask=None):
"""
Args:
x: Target tokens (batch_size, target_seq_len)
encoder_output: Output from encoder (batch_size, source_seq_len, d_model)
src_mask: Mask for source padding
tgt_mask: Mask for target padding and future positions
Returns:
decoder_output: (batch_size, target_seq_len, d_model)
"""
# 1. Pass through embedding layer and scale
x = self.embeddings(x) * self.scale
# 2. Add positional encoding and dropout
x = self.dropout(self.pe(x))
# 3. Pass through each decoder layer
for layer in self.decoder_layers:
x = layer(x, encoder_output, src_mask, tgt_mask)
return x
Utility Code
def create_padding_mask(seq):
"""
Create mask for padding tokens (0s)
Args:
seq: Input sequence tensor (batch_size, seq_len)
Returns:
mask: Padding mask (batch_size, 1, 1, seq_len)
"""
#YOUR CODE HERE
def create_future_mask(size):
"""
Create mask to prevent attention to future positions
Args:
size: Size of square mask (target_seq_len)
Returns:
mask: Future mask (1, 1, size, size)
"""
# Create upper triangular matrix and invert it
#YOUR CODE HERE
def create_masks(src, tgt):
"""
Create all masks needed for training
Args:
src: Source sequence (batch_size, src_len)
tgt: Target sequence (batch_size, tgt_len)
Returns:
src_mask: Padding mask for encoder
tgt_mask: Combined padding and future mask for decoder
"""
# 1. Create padding masks
#YOUR CODE HERE
# 2. Create future mask
#YOUR CODE HERE
# 3. Combine padding and future mask for target
# Both masks should be True for allowed positions
#YOUR CODE HERE
def create_padding_mask(seq):
"""
Create mask for padding tokens (0s)
Args:
seq: Input sequence tensor (batch_size, seq_len)
Returns:
mask: Padding mask (batch_size, 1, 1, seq_len)
"""
batch_size, seq_len = seq.shape
output = torch.eq(seq, 0).float()
return output.view(batch_size, 1, 1, seq_len)
def create_future_mask(size):
"""
Create mask to prevent attention to future positions
Args:
size: Size of square mask (target_seq_len)
Returns:
mask: Future mask (1, 1, size, size)
"""
# Create upper triangular matrix and invert it
mask = torch.triu(torch.ones((1, 1, size, size)), diagonal=1) == 0
return mask
def create_masks(src, tgt):
"""
Create all masks needed for training
Args:
src: Source sequence (batch_size, src_len)
tgt: Target sequence (batch_size, tgt_len)
Returns:
src_mask: Padding mask for encoder
tgt_mask: Combined padding and future mask for decoder
"""
# 1. Create padding masks
src_padding_mask = create_padding_mask(src)
tgt_padding_mask = create_padding_mask(tgt)
# 2. Create future mask
tgt_len = tgt.size(1)
tgt_future_mask = create_future_mask(tgt_len)
# 3. Combine padding and future mask for target
# Both masks should be True for allowed positions
tgt_mask = tgt_padding_mask & tgt_future_mask
return src_padding_mask, tgt_mask
Transformer
class Transformer(nn.Module):
def __init__(self,
src_vocab_size,
tgt_vocab_size,
d_model,
num_layers=6,
num_heads=8,
d_ff=2048,
dropout=0.1,
max_seq_length=5000):
super().__init__()
# Pass all necessary parameters to Encoder and Decoder
#YOUR CODE HERE
# The final linear layer should project from d_model to tgt_vocab_size
#YOUR CODE HERE
def forward(self, src, tgt):
# Create masks for source and target
#YOUR CODE HERE
# Pass through encoder
#YOUR CODE HERE
# Pass through decoder
#YOUR CODE HERE
# Project to vocabulary size
#YOUR CODE HERE
class Transformer(nn.Module):
def __init__(self,
src_vocab_size,
tgt_vocab_size,
d_model,
num_layers=6,
num_heads=8,
d_ff=2048,
dropout=0.1,
max_seq_length=5000):
super().__init__()
# Pass all necessary parameters to Encoder and Decoder
self.encoder = Encoder(
src_vocab_size,
d_model,
num_layers,
num_heads,
d_ff,
dropout,
max_seq_length
)
self.decoder = Decoder(
tgt_vocab_size,
d_model,
num_layers,
num_heads,
d_ff,
dropout,
max_seq_length
)
# The final linear layer should project from d_model to tgt_vocab_size
self.final_layer = nn.Linear(d_model, tgt_vocab_size)
def forward(self, src, tgt):
# Create masks for source and target
src_mask, tgt_mask = create_masks(src, tgt)
# Pass through encoder
encoder_output = self.encoder(src, src_mask)
# Pass through decoder
decoder_output = self.decoder(tgt, encoder_output, src_mask, tgt_mask)
# Project to vocabulary size
output = self.final_layer(decoder_output)
# Note: Usually don't apply softmax here if using CrossEntropyLoss
# as it applies log_softmax internally
return output
Utility code for Transformer
class TransformerLRScheduler:
def __init__(self, optimizer, d_model, warmup_steps):
"""
Args:
optimizer: Optimizer to adjust learning rate for
d_model: Model dimensionality
warmup_steps: Number of warmup steps
"""
self.optimizer = optimizer
self.d_model = d_model
self.warmup_steps = warmup_steps
def step(self, step_num):
"""
Update learning rate based on step number
"""
# lrate = d_model^(-0.5) * min(step_num^(-0.5), step_num * warmup_steps^(-1.5))
#YOUR CODE HERE
class LabelSmoothing(nn.Module):
def __init__(self, smoothing=0.1):
super().__init__()
self.smoothing = smoothing
self.confidence = 1.0 - smoothing
def forward(self, logits, target):
"""
Args:
logits: Model predictions (batch_size, vocab_size) #each row of vocab_size contains probability score of each label
target: True labels (batch_size) #each row of batch size contains the index to the correct label
"""
#Note: make sure to not save the gradients of these
# Create a soft target distribution
#create the zeros [0,0,...]
#fill with calculated value [0.000125..,0.000125...] (this is an arbitarary value for example purposes)
#add 1 to the correct index (read more on docs of pytorch)
#return cross entropy loss
class TransformerLRScheduler:
def __init__(self, optimizer, d_model, warmup_steps):
"""
Args:
optimizer: Optimizer to adjust learning rate for
d_model: Model dimensionality
warmup_steps: Number of warmup steps
"""
# Your code here
# lrate = d_model^(-0.5) * min(step_num^(-0.5), step_num * warmup_steps^(-1.5))
self.optimizer = optimizer
self.d_model = d_model
self.warmup_steps = warmup_steps
def step(self, step_num):
"""
Update learning rate based on step number
"""
# Your code here - implement the formula
lrate = torch.pow(self.d_model,-0.5)*torch.min(torch.pow(step_num,-0.5), torch.tensor(step_num) * torch.pow(self.warmup_steps,-1.5))
class LabelSmoothing(nn.Module):
def __init__(self, smoothing=0.1):
super().__init__()
self.smoothing = smoothing
self.confidence = 1.0 - smoothing
def forward(self, logits, target):
"""
Args:
logits: Model predictions (batch_size, vocab_size) #each row of vocab_size contains probability score of each label
target: True labels (batch_size) #each row of batch size contains the index to the correct label
"""
vocab_size = logits.size(-1)
with torch.no_grad():
# Create a soft target distribution
true_dist = torch.zeros_like(logits) #create the zeros [0,0,...]
true_dist.fill_(self.smoothing / (vocab_size - 1)) #fill with calculated value [0.000125..,0.000125...] (this is an arbitarary value for example purposes)
true_dist.scatter_(1, target.unsqueeze(1), self.confidence) #add 1 to the correct index (read more on docs of pytorch)
return torch.mean(torch.sum(-true_dist * torch.log_softmax(logits, dim=-1), dim=-1)) #return cross entropy loss
Training transformers
def train_transformer(model, train_dataloader, criterion, optimizer, scheduler, num_epochs, device='cuda'):
"""
Training loop for transformer
Args:
model: Transformer model
train_dataloader: DataLoader for training data
criterion: Loss function (with label smoothing)
optimizer: Optimizer
scheduler: Learning rate scheduler
num_epochs: Number of training epochs
"""
# 1. Setup
# 2. Training loop
def train_transformer(model, train_dataloader, criterion, optimizer, scheduler, num_epochs, device='cuda'):
"""
Training loop for transformer
Args:
model: Transformer model
train_dataloader: DataLoader for training data
criterion: Loss function (with label smoothing)
optimizer: Optimizer
scheduler: Learning rate scheduler
num_epochs: Number of training epochs
"""
# 1. Setup
model = model.to(device)
model.train()
# For tracking training progress
total_loss = 0
all_losses = []
# 2. Training loop
for epoch in range(num_epochs):
print(f"Epoch {epoch + 1}/{num_epochs}")
epoch_loss = 0
for batch_idx, batch in enumerate(train_dataloader):
# Get source and target batches
src = batch['src'].to(device)
tgt = batch['tgt'].to(device)
# Create masks
src_mask, tgt_mask = create_masks(src, tgt)
# Prepare target for input and output
# Remove last token from target for input
tgt_input = tgt[:, :-1]
# Remove first token from target for output
tgt_output = tgt[:, 1:]
# Zero gradients
optimizer.zero_grad()
# Forward pass
outputs = model(src, tgt_input, src_mask, tgt_mask)
# Reshape outputs and target for loss calculation
outputs = outputs.view(-1, outputs.size(-1))
tgt_output = tgt_output.view(-1)
# Calculate loss
loss = criterion(outputs, tgt_output)
# Backward pass
loss.backward()
# Clip gradients
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
# Update weights
optimizer.step()
scheduler.step()
# Update loss tracking
epoch_loss += loss.item()
# Print progress every N batches
if batch_idx % 100 == 0:
print(f"Batch {batch_idx}, Loss: {loss.item():.4f}")
# Calculate average loss for epoch
avg_epoch_loss = epoch_loss / len(train_dataloader)
all_losses.append(avg_epoch_loss)
print(f"Epoch {epoch + 1} Loss: {avg_epoch_loss:.4f}")
# Save checkpoint
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': avg_epoch_loss,
}, f'checkpoint_epoch_{epoch+1}.pt')
return all_losses
Setting up the Dataset and DataLoader
import os
import torch
import spacy
import urllib.request
import zipfile
from torch.utils.data import Dataset, DataLoader
def download_multi30k():
"""Download Multi30k dataset if not present"""
# Create data directory
if not os.path.exists('data'):
os.makedirs('data')
# Download files if they don't exist
base_url = "https://raw.githubusercontent.com/multi30k/dataset/master/data/task1/raw/"
files = {
"train.de": "train.de.gz",
"train.en": "train.en.gz",
"val.de": "val.de.gz",
"val.en": "val.en.gz",
"test.de": "test_2016_flickr.de.gz",
"test.en": "test_2016_flickr.en.gz"
}
for local_name, remote_name in files.items():
filepath = f'data/{local_name}'
if not os.path.exists(filepath):
url = base_url + remote_name
urllib.request.urlretrieve(url, filepath + '.gz')
os.system(f'gunzip -f {filepath}.gz')
def load_data(filename):
"""Load data from file"""
with open(filename, 'r', encoding='utf-8') as f:
return [line.strip() for line in f]
def create_dataset():
"""Create dataset from files"""
# Download data if needed
download_multi30k()
# Load data
train_de = load_data('data/train.de')
train_en = load_data('data/train.en')
val_de = load_data('data/val.de')
val_en = load_data('data/val.en')
return (train_de, train_en), (val_de, val_en)
class TranslationDataset(Dataset):
def __init__(self, src_texts, tgt_texts, src_vocab, tgt_vocab, src_tokenizer, tgt_tokenizer):
self.src_texts = src_texts
self.tgt_texts = tgt_texts
self.src_vocab = src_vocab
self.tgt_vocab = tgt_vocab
self.src_tokenizer = src_tokenizer
self.tgt_tokenizer = tgt_tokenizer
def __len__(self):
return len(self.src_texts)
def __getitem__(self, idx):
src_text = self.src_texts[idx]
tgt_text = self.tgt_texts[idx]
# Tokenize
src_tokens = [tok.text for tok in self.src_tokenizer(src_text)]
tgt_tokens = [tok.text for tok in self.tgt_tokenizer(tgt_text)]
# Convert to indices
src_indices = [self.src_vocab["<s>"]] + [self.src_vocab[token] for token in src_tokens] + [self.src_vocab["</s>"]]
tgt_indices = [self.tgt_vocab["<s>"]] + [self.tgt_vocab[token] for token in tgt_tokens] + [self.tgt_vocab["</s>"]]
return {
'src': torch.tensor(src_indices),
'tgt': torch.tensor(tgt_indices)
}
def build_vocab_from_texts(texts, tokenizer, min_freq=2):
"""Build vocabulary from texts"""
counter = {}
for text in texts:
for token in [tok.text for tok in tokenizer(text)]:
counter[token] = counter.get(token, 0) + 1
# Create vocabulary
vocab = {"<s>": 0, "</s>": 1, "<blank>": 2, "<unk>": 3}
idx = 4
for word, freq in counter.items():
if freq >= min_freq:
vocab[word] = idx
idx += 1
return vocab
def create_dataloaders(batch_size=32):
# Load tokenizers
spacy_de = spacy.load("de_core_news_sm")
spacy_en = spacy.load("en_core_web_sm")
# Get data
(train_de, train_en), (val_de, val_en) = create_dataset()
# Build vocabularies
vocab_src = build_vocab_from_texts(train_de, spacy_de)
vocab_tgt = build_vocab_from_texts(train_en, spacy_en)
# Create datasets
train_dataset = TranslationDataset(
train_de, train_en,
vocab_src, vocab_tgt,
spacy_de, spacy_en
)
val_dataset = TranslationDataset(
val_de, val_en,
vocab_src, vocab_tgt,
spacy_de, spacy_en
)
# Create dataloaders
train_dataloader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
collate_fn=collate_batch
)
val_dataloader = DataLoader(
val_dataset,
batch_size=batch_size,
shuffle=False,
collate_fn=collate_batch
)
return train_dataloader, val_dataloader, vocab_src, vocab_tgt
def collate_batch(batch):
src_tensors = [item['src'] for item in batch]
tgt_tensors = [item['tgt'] for item in batch]
# Pad sequences
src_padded = torch.nn.utils.rnn.pad_sequence(src_tensors, batch_first=True, padding_value=2)
tgt_padded = torch.nn.utils.rnn.pad_sequence(tgt_tensors, batch_first=True, padding_value=2)
return {
'src': src_padded,
'tgt': tgt_padded
}
import os
import torch
import spacy
import urllib.request
import zipfile
from torch.utils.data import Dataset, DataLoader
def download_multi30k():
"""Download Multi30k dataset if not present"""
# Create data directory
if not os.path.exists('data'):
os.makedirs('data')
# Download files if they don't exist
base_url = "https://raw.githubusercontent.com/multi30k/dataset/master/data/task1/raw/"
files = {
"train.de": "train.de.gz",
"train.en": "train.en.gz",
"val.de": "val.de.gz",
"val.en": "val.en.gz",
"test.de": "test_2016_flickr.de.gz",
"test.en": "test_2016_flickr.en.gz"
}
for local_name, remote_name in files.items():
filepath = f'data/{local_name}'
if not os.path.exists(filepath):
url = base_url + remote_name
urllib.request.urlretrieve(url, filepath + '.gz')
os.system(f'gunzip -f {filepath}.gz')
def load_data(filename):
"""Load data from file"""
with open(filename, 'r', encoding='utf-8') as f:
return [line.strip() for line in f]
def create_dataset():
"""Create dataset from files"""
# Download data if needed
download_multi30k()
# Load data
train_de = load_data('data/train.de')
train_en = load_data('data/train.en')
val_de = load_data('data/val.de')
val_en = load_data('data/val.en')
return (train_de, train_en), (val_de, val_en)
class TranslationDataset(Dataset):
def __init__(self, src_texts, tgt_texts, src_vocab, tgt_vocab, src_tokenizer, tgt_tokenizer):
self.src_texts = src_texts
self.tgt_texts = tgt_texts
self.src_vocab = src_vocab
self.tgt_vocab = tgt_vocab
self.src_tokenizer = src_tokenizer
self.tgt_tokenizer = tgt_tokenizer
def __len__(self):
return len(self.src_texts)
def __getitem__(self, idx):
src_text = self.src_texts[idx]
tgt_text = self.tgt_texts[idx]
# Tokenize
src_tokens = [tok.text for tok in self.src_tokenizer(src_text)]
tgt_tokens = [tok.text for tok in self.tgt_tokenizer(tgt_text)]
# Convert to indices
src_indices = [self.src_vocab["<s>"]] + [self.src_vocab[token] for token in src_tokens] + [self.src_vocab["</s>"]]
tgt_indices = [self.tgt_vocab["<s>"]] + [self.tgt_vocab[token] for token in tgt_tokens] + [self.tgt_vocab["</s>"]]
return {
'src': torch.tensor(src_indices),
'tgt': torch.tensor(tgt_indices)
}
def build_vocab_from_texts(texts, tokenizer, min_freq=2):
"""Build vocabulary from texts"""
counter = {}
for text in texts:
for token in [tok.text for tok in tokenizer(text)]:
counter[token] = counter.get(token, 0) + 1
# Create vocabulary
vocab = {"<s>": 0, "</s>": 1, "<blank>": 2, "<unk>": 3}
idx = 4
for word, freq in counter.items():
if freq >= min_freq:
vocab[word] = idx
idx += 1
return vocab
def create_dataloaders(batch_size=32):
# Load tokenizers
spacy_de = spacy.load("de_core_news_sm")
spacy_en = spacy.load("en_core_web_sm")
# Get data
(train_de, train_en), (val_de, val_en) = create_dataset()
# Build vocabularies
vocab_src = build_vocab_from_texts(train_de, spacy_de)
vocab_tgt = build_vocab_from_texts(train_en, spacy_en)
# Create datasets
train_dataset = TranslationDataset(
train_de, train_en,
vocab_src, vocab_tgt,
spacy_de, spacy_en
)
val_dataset = TranslationDataset(
val_de, val_en,
vocab_src, vocab_tgt,
spacy_de, spacy_en
)
# Create dataloaders
train_dataloader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
collate_fn=collate_batch
)
val_dataloader = DataLoader(
val_dataset,
batch_size=batch_size,
shuffle=False,
collate_fn=collate_batch
)
return train_dataloader, val_dataloader, vocab_src, vocab_tgt
def collate_batch(batch):
src_tensors = [item['src'] for item in batch]
tgt_tensors = [item['tgt'] for item in batch]
# Pad sequences
src_padded = torch.nn.utils.rnn.pad_sequence(src_tensors, batch_first=True, padding_value=2)
tgt_padded = torch.nn.utils.rnn.pad_sequence(tgt_tensors, batch_first=True, padding_value=2)
return {
'src': src_padded,
'tgt': tgt_padded
}
Starting the training loop and Some Analysis (with tips for good convergence)
# Initialize your transformer with the vocabulary sizes
model = Transformer(
src_vocab_size=len(vocab_src),
tgt_vocab_size=len(vocab_tgt),
d_model=512,
num_layers=6,
num_heads=8,
d_ff=2048,
dropout=0.1
)
criterion = LabelSmoothing(smoothing=0.1).to(device)
# Now you can use your training loop
losses = train_transformer(
model=model,
train_dataloader=train_dataloader,
criterion=criterion,
optimizer=optimizer,
scheduler=scheduler,
num_epochs=10
)
Misc & Further Reading
Here are some resources and more information that can help you out in your journey which I could not decide where to put:
What is torch.nn really?
Neural networks by 3Blue1Brown
Congratulations on completing this tutorial/lesson/blog, however you see it. By nature of human curiosity, you must have a few questions now. Feel free to create issues on GitHub for those questions, and I will add any questions that I feel most beginners would have here.
Cheers, Pramod
Ways to help out
I have spent a considerable time trying to make this blog as close to my vision as possible, but to err is to be human. Feel free to raise a PR
if you do find any errors. I will be more than happy to accept them into the blog.
Also, I am always open to suggestions to improve the blog. Feel free to drop your thoughts in the issues
P.S All the code as well as assets can be accessed from my github and are free to use and distribute, Consider citing this work though :)
P.S.S I know there is a bit of issue with a few code samples, I will fix them within the week. This had been a work in progress for almost 3 months now. So I thought it’s better to publish something which is 95% done than to keep waiting for the perfect end product
Meme at top taken from xkcd
Comments